本文基于之前的分布式系统理论系列文章总结而成,本部分主要是实践内容,详细内容可见我的专栏:分布式系统理论与实践
https://blog.csdn.net/column/details/24090.html
本文主要是按照我自己的理解以及参考之前文章综合而成的,其中可能会有一些错误,还请见谅,也请指出。
分布式技术
分布式数据和nosql
分布式一般是指分布式部署的数据库。
比如Hbase基于HDFS分布式部署,所以他是一个分布式数据库。
当然MySQL也可以分布式部署,比如按照不同业务部署,或者把单表内容拆成多个表乃至多个库进行部署。
一般MySQL的扩展方式有:
1 主从复制 使用冗余保证可用
2 读写分离 主库负责写从库负责读,分担压力,并且保证数据一致性和备份。
3 分表分库,横向拆分数据表放到多个表中或者多个库中,一般多个表或者多个库会使用不同节点部署,也就是一种分布式方案,提高并发的读写量。
Nosql的话就比较多了,redis,memcache等。
当然hbase也是,hbase按照region将数据文件分布在hdfs上,并且hdfs提供高可用和备份,同时hbase的regionserver也保证高可用,于是hbase的分布式方案也是比较成熟的。
缓存 分布式缓存
一般作为缓存的软件有redis,memcache等。当然我本地写一个hashmap也可以作为缓存。
memcache提出了一致性哈希的算法,但是本身不支持数据持久化,也没有提供分布式方案,需要自己完成持久化以及分布式部署并且保证其可用性。
redis作为新兴的内存数据库,提供了比memcache更多的数据结构,以及各种分布式方案。当然它也支持持久化。
redis的部署方案:
1 redis的主从复制结构,和MySQL类似,使用日志aof或者持久化文件rdb进行主从同步。
2 读写分离,也可以做,但一般不需要。因为redis够快。
3 redis的哨兵方案,主节点配置哨兵,每当宕机时自动完成主从切换。
4 redis的集群方案,p2p的Redis Cluster部署了多台Redis服务器,每台Redis拥有全局的分片信息,所以任意节点都可以对外提供服务,当然每个节点只保存一部分分片,所以某台机器宕机时不会影响整个集群,当然每个节点也有slave,哨兵自动进行故障切换。
5 codis方案,codis屏蔽了集群的内部实现,可以不更改redis api的情况下使用代理的方式提供集群访问。并且使用 group的概念封装一组节点。
缓存需要解决的问题:
命中:缓存有数据
不命中:去数据库读取
失效:过期
替换:缓存淘汰算法。
一般有lru,fifo,随机缓存等。缓存更新的方法
缓存更新可以先更新数据库再更新缓存,也可以先更新缓存再更新数据库。
一般推荐先更新数据库,否则写一条数据时刚好有人读到缓存,把旧数据读到缓存中,此时新数据在数据库确不在缓存中。
还有一种方法,就是让缓存自己去完成数据库更新,而不是让应用去选择如何更新数据库,这样的话缓存和数据库的更新操作就是透明的了,我们只需要操作缓存即可。
缓存在springboot中的使用
springboot支持将缓存的curd操作配置在注解中,只需要在对应方法上配置好键和更新策略。
则redis会根据该方法的操作类型执行对应操作,非常方便。一致性哈希
分布式部署时,经常要面对的问题是,一个服务集群由谁来提供给这个客户度服务,需要一种算法来完成这一步映射。
如果直接使用hash显然分布非常不均匀。那如果使用余数法呢,一共有N台机器,我对N取余可以映射到任意一台机器上。
这种方法的缺点在于,当取余的值集中在某一范围时,就容易集中访问某些机器,导致热点问题。
于是memcache推出了一个叫做一致性哈希的算法,一个哈希环,环上支持2^32次方个节点,也就是包含了所有的ip。
然后我们把主机通过hash值分布到这个环上,请求到来时会映射到某一个节点,如果该节点没有主机,则顺时针寻找真正主机。
当节点加入或者节点删除时,并不会影响服务的可用性,只是某些请求会被映射到别的节点。
但是当请求集中到某个区域时,会产生倾斜,我们引入了虚拟节点来改善这个问题,虚拟节点对应到真实节点,所以加入虚拟节点可以更好地转移请求。
session和分布式session
session是web应用必备的一个结构。
一般有几种方案来管理session。
1 web应用保存session到内存中,但是宕机会丢失
2 web应用持久化到数据库或者redis,增加数据库负担。
3 使用cookie保存加密后的session,浏览器压力大,可能被破解
4 使用单独的session服务集群提供session服务,并且本身也可以采用分布式部署,部署的时候可以主从。
保证session一致性的解决方法(客户端可以访问到自己的session):
1 客户端cookie保存
2 多个webserver进行同步,效率低
3 反向代理绑定ip映射同一个服务器,但是宕机时出错
4 后端统一存储,比如redis,或则部署session服务。
负载均衡
负载均衡一般可以分为七层,四层负载均衡。
Nginx
七层的负载均衡也就是http负载均衡,主要使用Nginx完成。
配置Nginx进行反向代理的url,然后转发请求到上游服务器,请求进来时自动转发到上游服务器,通过url进行负载均衡,所以是七层负载均衡。既然是七层负载,那么上游服务器提供了http服务,也可以解析该请求。
四层负载均衡主要是tcp请求的负载均衡,因为tcp请求是绑定到一个端口上的,所以我们根据端口进行请求转发到上游服务器的。既然是四层负载,上游服务器监听该端口的服务就可以处理该请求。
LVS
LVS术语定义:
DS:Director Server,前端负载均衡器节点(后文用Director称呼);
RS:Real Server,后端真实服务器;
VIP:用户请求的目标的IP地址,一般是公网IP地址;
DIP:Director Server IP,Director和Real Server通讯的内网IP地址;
RIP:Real Server IP,Director和Real Server通讯的内网IP地址;LVS有三种实现负载均衡的方式
NAT 四层负载均衡
NAT支持四层负载均衡,NAT中只有DS提供公网ip,并且VIP绑定在DS的mac地址上,客户端只能访问DS。同时DS和RS通过内网ip进行网络连接。当TCP数据报到达DS时,DS修改数据报,指向RS的ip和port。进行转发即可。
同时,RS处理完请求后,由于网关时DS,所以仍然要返回给DS处理。
NAT模式中,RS返回数据包是返回给Director,Director再返回给客户端;事实上这跟NAT网络协议没什么关系。
DR 二层负载均衡
DR模式中,DS负责接收请求。接收请求后把数据报的mac地址改成指向RS的mac地址,并且由于三台机器拥有同样的vip地址。
所以RS接收请求后认为该数据报应该由自己处理并相应。同时为了避免RS再把相应转发会DS,我们禁用了对DS的arp,所以此时RS就会通过vip把响应通过vip网关返回给客户端。
Director通过修改请求中目标地址MAC为选定的RS实现数据转发,这就要求Diretor和Real Server必须在同一个广播域内,也就是他们的mac地址是可达的。
DR(Direct Routing)模式中,RS返回数据是直接返回给客户端(通过额外的路由);
TUN
TUN中使用了IP隧道技术,客户端请求发给DS时,DS会通过隧道技术把数据报通过隧道发给实际的RS,然后RS解析数据以后可以直接响应给客户端,因为他有客户端的ip地址。这就不要求DS和RS在同一网段了,当然前提是RS有公网ip。
TUN(IP Tunneling)模式中,RS返回的数据也是直接返回给客户端,这种模式通过Overlay协议(把一个IP数据包封装到另一个数据包内部叫Overlay)避免了DR的限制。
zookeeper
zookeeper集群自身的特性:
1 一个zookeeper服务器集群,一开始就会进行选主,主节点挂掉后也会进行选主。
使用zab协议中的选主机制进行选主,也就是每个节点进行一次提议,刚开始提议自己,如果有新的提议则覆盖自己原来的提议,不断重复,直到有节点获得过半的投票。完成一轮选主。
2 选主结束后,开始进行消息广播和数据同步,保证每一台服务器的数据都和leader同步。
3 开始提供服务,客户端向leader发送请求,leader首先发出提议,当有半数以上节点响应时,leader会发送commit信息,于是所有节点执行该操作。当有机器宕机时重启后会和leader同步。这是一个类似2pc的提交方式。
zookeeper提供了分布式环境中常用的服务
1 配置服务,多个机器可以通过文件节点共享配置。
2 选主服务,通过添加顺序节点,可以进行选主。
3 分布式锁,顺序节点和watcher
4 全局id,使用机器号+时间戳可以生成一个transactionid,是全局唯一的。
数据库的分布式事务
分布式事务的实现一般可以用2PC和3PC解决。
成熟的方案有:
1 TCC 补偿式事务,对每一个步骤都有一个补偿措施。
2 全局事务实现。
3 事务消息:rocketmq的事务实现,先发消息到队列中,然后本地执行事务并通知消息队列,若成功则消息主动推给另一个服务,直到服务二执行成功,消息从队列中删除。如果超时不成功,则消息要求事务A回滚。
如果过程中失败了,本地事务也会回滚。消息队列可以回调本地接口判断事务是否执行成功,防止超时。
4 本地实现消息表:
本地实现消息表并且和事务记录存在一起,自己实现消息的轮询发送。
首先把本地事务操作和消息增加放在一个事务里执行,然后轮询消息表进行发送,如果执行成功则消息达到服务B,通知其执行。执行成功后消息被删除,否则回滚事务删除消息。
分布式锁问题
分布式锁用于分布式环境中的资源互斥,因为单机可以通过共享内存实现,而分布式环境只能通过网络实现。
MySQL实现分布式锁
insert加锁,锁没有失效时间,容易产生死锁redis实现分布式锁
1. 基于setnx、expire两个命令来实现
基于setnx(set if not exist)的特点,当缓存里key不存在时,才会去set,否则直接返回false。
如果返回true则获取到锁,否则获取锁失败,为了防止死锁,我们再用expire命令对这个key设置一个超时时间来避免。
但是这里看似完美,实则有缺陷,当我们setnx成功后,线程发生异常中断,expire还没来的及设置,那么就会产生死锁。
2 使用getset实现,可以判断自己是否获得了锁,但是可能会出现并发的原子性问题。拆分成两个操作。
3 避免原子性问题可以使用lua脚本保证事务的原子性。
4 上述都是单点的redis,如果是分布式环境的redis集群,可以使用redlock,要求节点向半数以上redis机器请求锁。才算成功。zookeeper实现分布式锁
创建有序节点,最小的抢到锁,其他的监听他的上一个节点即可。并且抢到锁的节点释放时只会通知下一个节点。
小结
在分布式系统中,共享资源互斥访问问题非常普遍,而针对访问共享资源的互斥问题,常用的解决方案就是使用分布式锁,这里只介绍了几种常用的分布式锁,分布式锁的实现方式还有有很多种,根据业务选择合适的分布式锁,下面对上述几种锁进行一下比较:
数据库锁:
优点:直接使用数据库,使用简单。
缺点:分布式系统大多数瓶颈都在数据库,使用数据库锁会增加数据库负担。
缓存锁:
优点:性能高,实现起来较为方便,在允许偶发的锁失效情况,不影响系统正常使用,建议采用缓存锁。
缺点:通过锁超时机制不是十分可靠,当线程获得锁后,处理时间过长导致锁超时,就失效了锁的作用。
zookeeper锁:
优点:不依靠超时时间释放锁;可靠性高;系统要求高可靠性时,建议采用zookeeper锁。
缺点:性能比不上缓存锁,因为要频繁的创建节点删除节点。并且zookeeper只能单点写入。而Redis可以并发写入。消息队列
适合场景:
1 服务之间解耦,比如淘宝的买家服务和物流服务,中间需要消息传递订单信息。但又不需要强耦合。便于服务的划分和独立部署
2 控制流量,大流量访问某服务时,避免服务出现问题,将其先存入队列,均匀释放流量。
3 削峰,当某一个服务如秒杀,如果直接集中访问,服务器可能会冲垮,所以先存到队列中,控制访问量,避免服务器冲击。
4 事务,消息事务
5 异步请求处理,比如一些不重要的服务可以延缓执行,比如卖家评价,站内信等。
常用消息队列:
rabbitmq:使用consumer和producer的模型,并且使用了broker,broker中包含路由功能的exchanger,每个key绑定一个queue,应用通过key进行队列消费和生产。
一般是点对点的消息,也可以支持一对多的消息,当然也可以支持消息的订阅。还有就是主题模式,和key的区别就是主题模式是多级的key表示。
kafka:
微服务和Dubbo
分布式架构意味着服务的拆分,最早的SOA架构已经进行了服务拆分,但是每个服务还是太过庞大,不适合扩展和修改。
微服务的拆分粒度更加细,服务可以独立部署和快速迭代,通知支持扩展。
服务之间一般使用rpc调用进行访问,可以使用自定义协议也可以使用http服务,当然通过netty 实现TCP服务并且搭配合理的序列化方案也可以完成rpc功能。rpc是微服务的基础。
微服务一般需要配置中心来进行服务注册和发现,以便服务信息更新和配置,dubbo中使用的是zookeeper,用于配置服务信息提供给生产者使用。
一般情况下微服务需要有监控中心,心跳检测每一台服务器,及时完成故障切换和通知。同时监控服务的性能和使用情况。
序列化方式一般可以使用protobuf,http服务一般使用json。
微服务还支持更多的包括权限控制,流量控制,灰度发布,服务降级等内容,这里就不再细谈。
全局id
方法一:使用数据库的 auto_increment 来生成全局唯一递增ID
优点:
简单,使用数据库已有的功能
能够保证唯一性
能够保证递增性
步长固定
缺点:
可用性难以保证:数据库常见架构是一主多从+读写分离,生成自增ID是写请求,主库挂了就玩不转了
扩展性差,性能有上限:因为写入是单点,数据库主库的写性能决定ID的生成性能上限,并且难以扩展方法三:uuid/guid
不管是通过数据库,还是通过服务来生成ID,业务方Application都需要进行一次远程调用,比较耗时。
有没有一种本地生成ID的方法,即高性能,又时延低呢?
uuid是一种常见的方案:
string ID =GenUUID();
优点:
本地生成ID,不需要进行远程调用,时延低
扩展性好,基本可以认为没有性能上限
缺点:
无法保证趋势递增
uuid过长,往往用字符串表示,作为主键建立索引查询效率低,常见优化方案为“转化为两个uint64整数存储”或者“折半存储”(折半后不能保证唯一性)
方法四:取当前毫秒数
uuid是一个本地算法,生成性能高,但无法保证趋势递增,且作为字符串ID检索效率低,有没有一种能保证递增的本地算法呢?
取当前毫秒数是一种常见方案:
uint64 ID = GenTimeMS();
优点:
本地生成ID,不需要进行远程调用,时延低
生成的ID趋势递增
生成的ID是整数,建立索引后查询效率高
缺点:
如果并发量超过1000,会生成重复的ID
方法五:类snowflake算法
snowflake是twitter开源的分布式ID生成算法,其核心思想为,一个long型的ID:
41bit作为毫秒数
10bit作为机器编号
12bit作为毫秒内序列号
算法单机每秒内理论上最多可以生成1000*(2^12),也就是400W的ID,完全能满足业务的需求。
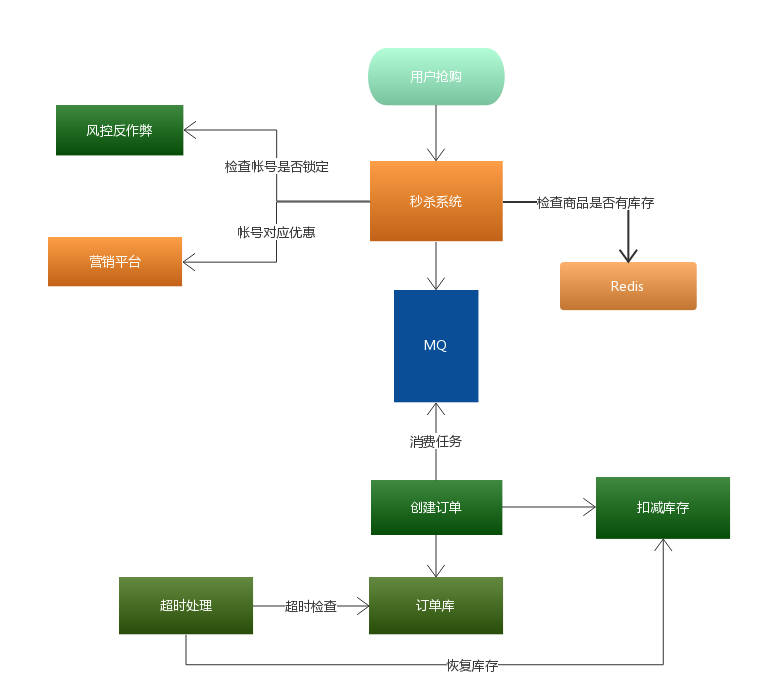
秒杀系统

第一层,客户端怎么优化(浏览器层,APP层)
(a)产品层面,用户点击“查询”或者“购票”后,按钮置灰,禁止用户重复提交请求;
(b)JS层面,限制用户在x秒之内只能提交一次请求;
第二层,站点层面的请求拦截
怎么拦截?怎么防止程序员写for循环调用,有去重依据么?ip?cookie-id?…想复杂了,这类业务都需要登录,用uid即可。在站点层面,对uid进行请求计数和去重,甚至不需要统一存储计数,直接站点层内存存储(这样计数会不准,但最简单)。一个uid,5秒只准透过1个请求,这样又能拦住99%的for循环请求。
5s只透过一个请求,其余的请求怎么办?缓存,页面缓存,同一个uid,限制访问频度,做页面缓存,x秒内到达站点层的请求,均返回同一页面。同一个item的查询,例如车次,做页面缓存,x秒内到达站点层的请求,均返回同一页面。如此限流,既能保证用户有良好的用户体验(没有返回404)又能保证系统的健壮性(利用页面缓存,把请求拦截在站点层了)。
好,这个方式拦住了写for循环发http请求的程序员,有些高端程序员(黑客)控制了10w个肉鸡,手里有10w个uid,同时发请求(先不考虑实名制的问题,小米抢手机不需要实名制),这下怎么办,站点层按照uid限流拦不住了。
第三层 服务层来拦截(反正就是不要让请求落到数据库上去)消息队列+缓存
服务层怎么拦截?大哥,我是服务层,我清楚的知道小米只有1万部手机,我清楚的知道一列火车只有2000张车票,我透10w个请求去数据库有什么意义呢?没错,请求队列!
对于写请求,做请求队列,每次只透有限的写请求去数据层(下订单,支付这样的写业务)
1w部手机,只透1w个下单请求去db
3k张火车票,只透3k个下单请求去db
如果均成功再放下一批,如果库存不够则队列里的写请求全部返回“已售完”。
对于读请求,怎么优化?cache抗,不管是memcached还是redis,单机抗个每秒10w应该都是没什么问题的。如此限流,只有非常少的写请求,和非常少的读缓存mis的请求会透到数据层去,又有99.9%的请求被拦住了。
好了,最后是数据库层
浏览器拦截了80%,站点层拦截了99.9%并做了页面缓存,服务层又做了写请求队列与数据缓存,每次透到数据库层的请求都是可控的。db基本就没什么压力了,闲庭信步,单机也能扛得住,还是那句话,库存是有限的,小米的产能有限,透这么多请求来数据库没有意义。
全部透到数据库,100w个下单,0个成功,请求有效率0%。透3k个到数据,全部成功,请求有效率100%。
总结
上文应该描述的非常清楚了,没什么总结了,对于秒杀系统,再次重复下我个人经验的两个架构优化思路:
(1)尽量将请求拦截在系统上游(越上游越好);
(2)读多写少的常用多使用缓存(缓存抗读压力);
浏览器和APP:做限速
站点层:按照uid做限速,做页面缓存
服务层:按照业务做写请求队列控制流量,做数据缓存
数据层:闲庭信步
并且:结合业务做优化
微信公众号
个人公众号:程序员黄小斜
微信公众号【程序员黄小斜】新生代青年聚集地,程序员成长充电站。作者黄小斜,职业是阿里程序员,身份是斜杠青年,希望和更多的程序员交朋友,一起进步和成长!这一次,我们一起出发。
关注公众号后回复“2019”领取我这两年整理的学习资料,涵盖自学编程、求职面试、算法刷题、Java技术、计算机基础和考研等8000G资料合集。

技术公众号:Java技术江湖
微信公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,专注于 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
关注公众号后回复“PDF”即可领取200+页的《Java工程师面试指南》强烈推荐,几乎涵盖所有Java工程师必知必会的知识点。


