本文基于之前的分布式系统理论系列文章总结而成,主要是理论部分,详细内容可见我的专栏:分布式系统理论与实践
https://blog.csdn.net/column/details/24090.html
本文主要是按照我自己的理解以及参考之前文章综合而成的,其中可能会有一些错误,还请见谅,也请指出。
分布式理论
CAP
CAP定理讲的是三个性。consistency数据一致性,availability可用性,partition tolerance分区容错性。
三者只能选其中两者。为什么呢,看看这三个性质意味着什么吧。
首先看看分区容错性,分区容错性指的是网络出现分区(丢包,断网,超时等情况都属于网络分区)时,整个服务仍然可用。
由于网络分区在实际环境下一定存在,所以必须首先被考虑。于是分区容错性是必须要保证的,否则一旦出现分区服务就不可用,那就没办法弄了。
所以实际上是2选1的问题。在可用性和一致性中做出选择。
在一个分布式环境下,多个节点一起对外提供服务,如果要保证可用性,那么一台机器宕机了仍然有其他机器能提供服务。
但是宕机的机器重启以后就会发现数据和其他机器存在不一致,那么一致性就无法得到保证。
如果保证一致性,如果有机器宕机,那么其他节点就不能工作了,否则一定会产生数据不一致。
BASE
在这么严苛的规定下,CAP一般很难实现一个健壮的系统。于是提出了BASE来削弱这些要求。
BASE是基本可用basically available,soft state软状态,eventually consistent最终一致性。
基本可用就是允许服务在某些时候降级,比如淘宝在高峰时期会关闭退货等服务。
软状态就是允许数据出现中间状态,比如支付宝提交转账以后并不是立刻到账,中间经过了多次消息传递和转发。
最终一致性就是指数据最终要是一致的,比如多个节点的数据需要定期同步,支付宝转账最终一定会到账。
分布式系统关键词
时钟,时间,事件顺序
分布式系统的一个问题在与缺少全局时钟,所以大家没有一个统一的时间,就很难用时间去确定各个节点事件的发生顺序,为了保证事件的顺序执行,
Lamport timestamps
Leslie Lamport 在1978年提出逻辑时钟的概念,并描述了一种逻辑时钟的表示方法,这个方法被称为Lamport时间戳(Lamport timestamps)[3]。
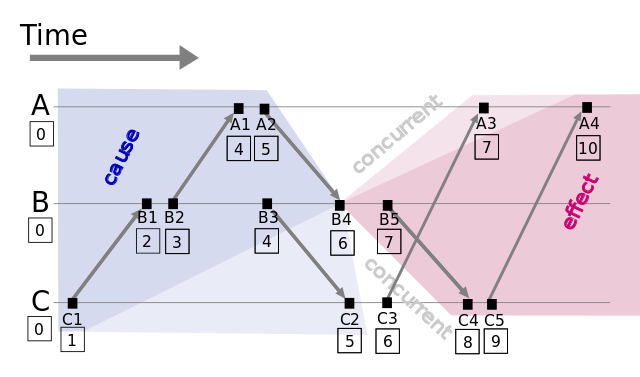
分布式系统中按是否存在节点交互可分为三类事件,一类发生于节点内部,二是发送事件,三是接收事件。Lamport时间戳原理如下:
每个事件对应一个Lamport时间戳,初始值为0
如果事件在节点内发生,时间戳加1
如果事件属于发送事件,时间戳加1并在消息中带上该时间戳
如果事件属于接收事件,时间戳 = Max(本地时间戳,消息中的时间戳) + 1这样的话,节点内的事件有序,发送事件有序,接收事件一定在发送事件以后发生。再加上人为的一些规定,因此根据时间戳可以确定一个全序排列。
Vector clock
Lamport时间戳帮助我们得到事件顺序关系,但还有一种顺序关系不能用Lamport时间戳很好地表示出来,那就是同时发生关系(concurrent)[4]。
Vector clock是在Lamport时间戳基础上演进的另一种逻辑时钟方法,它通过vector结构不但记录本节点的Lamport时间戳,同时也记录了其他节点的Lamport时间戳[5][6]。
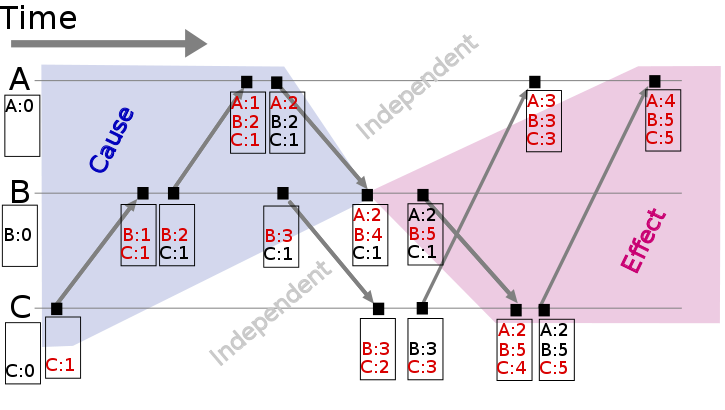
如果 Tb[Q] > Ta[Q] 并且 Tb[P] < Ta[P],则认为a、b同时发生,记作 a <-> b。例如图2中节点B上的第4个事件 (A:2,B:4,C:1) 与节点C上的第2个事件 (B:3,C:2) 没有因果关系、属于同时发生事件。
因为B4 > B3并且 C1<C2,说明两者之间没有顺序关系,否则不会出现一大一小,因此他们是同时发生的。
Version vector
基于Vector clock我们可以获得任意两个事件的顺序关系,结果或为先后顺序或为同时发生,识别事件顺序在工程实践中有很重要的引申应用,最常见的应用是发现数据冲突(detect conflict)。
分布式系统中数据一般存在多个副本(replication),多个副本可能被同时更新,这会引起副本间数据不一致[7],Version vector的实现与Vector clock非常类似[8],目的用于发现数据冲突[9]。
当两个写入数据事件同时发生则发生了冲突,于是通过某些方法解决数据冲突。
Vector clock只用于发现数据冲突,不能解决数据冲突。如何解决数据冲突因场景而异,具体方法有以最后更新为准(last write win),或将冲突的数据交给client由client端决定如何处理,或通过quorum决议事先避免数据冲突的情况发生[11]。
选主,租约,多数派
选举(election)是分布式系统实践中常见的问题,通过打破节点间的对等关系,选得的leader(或叫master、coordinator)有助于实现事务原子性、提升决议效率。
多数派(quorum)的思路帮助我们在网络分化的情况下达成决议一致性,在leader选举的场景下帮助我们选出唯一leader。
租约(lease)在一定期限内给予节点特定权利,也可以用于实现leader选举。
选举(electioin)
一致性问题(consistency)是独立的节点间如何达成决议的问题,选出大家都认可的leader本质上也是一致性问题,因而如何应对宕机恢复、网络分化等在leader选举中也需要考量。
在一致性算法Paxos、ZAB[2]、Raft[3]中,为提升决议效率均有节点充当leader的角色。
ZAB、Raft中描述了具体的leader选举实现,与Bully算法类似ZAB中使用zxid标识节点,具有最大zxid的节点表示其所具备的事务(transaction)最新、被选为leader。
多数派(quorum)
在网络分化的场景下以上Bully算法会遇到一个问题,被分隔的节点都认为自己具有最大的序号、将产生多个leader,这时候就需要引入多数派(quorum)[4]。多数派的思路在分布式系统中很常见,其确保网络分化情况下决议唯一。
租约(lease)
选举中很重要的一个问题,以上尚未提到:怎么判断leader不可用、什么时候应该发起重新选举?
最先可能想到会通过心跳(heart beat)判别leader状态是否正常,但在网络拥塞或瞬断的情况下,这容易导致出现双主。
租约(lease)是解决该问题的常用方法,其最初提出时用于解决分布式缓存一致性问题[6],后面在分布式锁[7]等很多方面都有应用。
(a). 节点0、1、2在Z上注册自己,Z根据一定的规则(例如先到先得)颁发租约给节点,该租约同时对应一个有效时长;这里假设节点0获得租约、成为leader
(b). leader宕机时,只有租约到期(timeout)后才重新发起选举,这里节点1获得租约、成为leader租约机制确保了一个时刻最多只有一个leader,避免只使用心跳机制产生双主的问题。在实践应用中,zookeeper、ectd可用于租约颁发。
一致性,2pc和3pc
一致性(consensus)
何为一致性问题?简单而言,一致性问题就是相互独立的节点之间如何达成一项决议的问题。分布式系统中,进行数据库事务提交(commit transaction)、Leader选举、序列号生成等都会遇到一致性问题。
为了保证执行的一致性,可以使用2pc两段式提交和3pc三段式提交。
2PC
2PC(tow phase commit)两阶段提交[5]顾名思义它分成两个阶段,先由一方进行提议(propose)并收集其他节点的反馈(vote),再根据反馈决定提交(commit)或中止(abort)事务。我们将提议的节点称为协调者(coordinator),其他参与决议节点称为参与者(participants, 或cohorts):
举个例子,首先用户想要执行一个事务,于是提交给leader,leader先让各个节点执行该事务。
我们要知道,事务是通过日志来实现的。各个节点使用redo日志进行重做,使用undo日志进行回滚。
于是各个节点执行事务,并把执行结果是否成功返回给leader,当leader收到全部确认消息后,发送消息让所有节点commit。如果有节点执行失败,则leader要求所有节点回滚。
2pc可能出现的一些问题是:
1 leader必须等待所有节点结果,如果有节点宕机或超时,则拒绝该事务,并向节点发送回滚的信息。
2 如果leader宕机,则一般配置watcherdog自动切换成备用leader,然后进行下一次的请求提交。
3这两种情况单独发生时都没有关系,有对应的措施可以进行回滚,但是如果当一个节点宕机时leader正在等待所有节点消息,其他节点也在等待leader最后的消息。
此时leader也不幸宕机,切换之后leader并不知道一个节点宕机了,这样的话其他的节点也会被阻塞住导致无法回滚。
3PC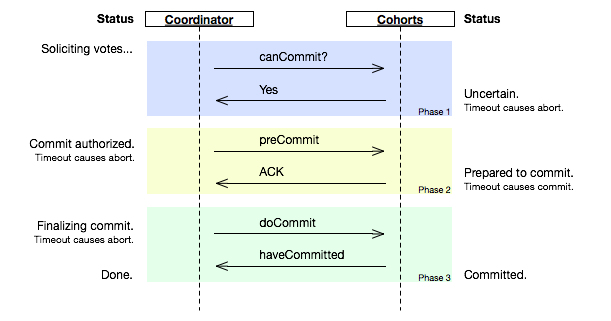
coordinator接收完participant的反馈(vote)之后,进入阶段2,给各个participant发送准备提交(prepare to commit)指令
。participant接到准备提交指令后可以锁资源,但要求相关操作必须可回滚。coordinator接收完确认(ACK)后进入阶段3、进行commit/abort,3PC的阶段3与2PC的阶段2无异。协调者备份(coordinator watchdog)、状态记录(logging)同样应用在3PC。
participant如果在不同阶段宕机,我们来看看3PC如何应对:
阶段1: coordinator或watchdog未收到宕机participant的vote,直接中止事务;宕机的participant恢复后,读取logging发现未发出赞成vote,自行中止该次事务
阶段2: coordinator未收到宕机participant的precommit ACK,但因为之前已经收到了宕机participant的赞成反馈(不然也不会进入到阶段2),coordinator进行commit;watchdog可以通过问询其他participant获得这些信息,过程同理;宕机的participant恢复后发现收到precommit或已经发出赞成vote,则自行commit该次事务
阶段3: 即便coordinator或watchdog未收到宕机participant的commit ACK,也结束该次事务;宕机的participant恢复后发现收到commit或者precommit,也将自行commit该次事务
因为有了准备提交(prepare to
commit)阶段,3PC的事务处理延时也增加了1个RTT,变为3个RTT(propose+precommit+commit),但是它防止participant宕机后整个系统进入阻塞态,增强了系统的可用性,对一些现实业务场景是非常值得的。
总结一下就是:阶段一leader要求节点准备,节点返回ack或者fail。
如果节点都是ack,leader返回ack进入阶段二。
(如果fail则回滚,因为节点没有接收到ack,所以最终都会回滚)
阶段二时节点执行事务并且发送结果给leader,leader返回ack或者fail。由于阶段二的节点已经有了一个确定的状态ack,如果leader超时或宕机不返回,成功执行节点也会进行commit操作,这样即使有节点宕机也不会影响到其他节点。
一致性算法paxos
Basic Paxos
何为一致性问题?简单而言,一致性问题是在节点宕机、消息无序等场景可能出现的情况下,相互独立的节点之间如何达成决议的问题,作为解决一致性问题的协议,Paxos的核心是节点间如何确定并只确定一个值(value)。
和2PC类似,Paxos先把节点分成两类,发起提议(proposal)的一方为proposer,参与决议的一方为acceptor。假如只有一个proposer发起提议,并且节点不宕机、消息不丢包,那么acceptor做到以下这点就可以确定一个值。
proposer发出提议,acceptor根据提议的id和值来决定是否接收提议,接受提议则替换为自己的提议,并且返回之前id最大的提议,当超过一半节点提议该值时,则该值被确定,这样既保证了时序,也保证了多数派。
Multi Paxos
通过以上步骤分布式系统已经能确定一个值,“只确定一个值有什么用?这可解决不了我面临的问题。” 你心中可能有这样的疑问。
其实不断地进行“确定一个值”的过程、再为每个过程编上序号,就能得到具有全序关系(total order)的系列值,进而能应用在数据库副本存储等很多场景。我们把单次“确定一个值”的过程称为实例(instance),它由proposer/acceptor/learner组成。
Fast Paxos
在Multi Paxos中,proposer -> leader -> acceptor -> learner,从提议到完成决议共经过3次通信,能不能减少通信步骤?
对Multi Paxos phase2a,如果可以自由提议value,则可以让proposer直接发起提议、leader退出通信过程,变为proposer -> acceptor -> learner,这就是Fast Paxos[2]的由来。
多次paxos的确定值使用可以让多个proposer,acceptor一起运作。多个proposer提出提议,acceptor保留最大提议比返回之前提议,proposer当提议数量满足多数派则取出最大值向acceptor提议,于是过半数的acceptor比较提议后可以接受该提议,于是最终leader将提议写入acceptor,而acceptor再写入对应的learner。
raft和zab
Zab
Zab[5][6]的全称是Zookeeper atomic broadcast protocol,是Zookeeper内部用到的一致性协议。相比Paxos,Zab最大的特点是保证强一致性(strong consistency,或叫线性一致性linearizable consistency)。
和Raft一样,Zab要求唯一Leader参与决议,Zab可以分解成discovery、sync、broadcast三个阶段:
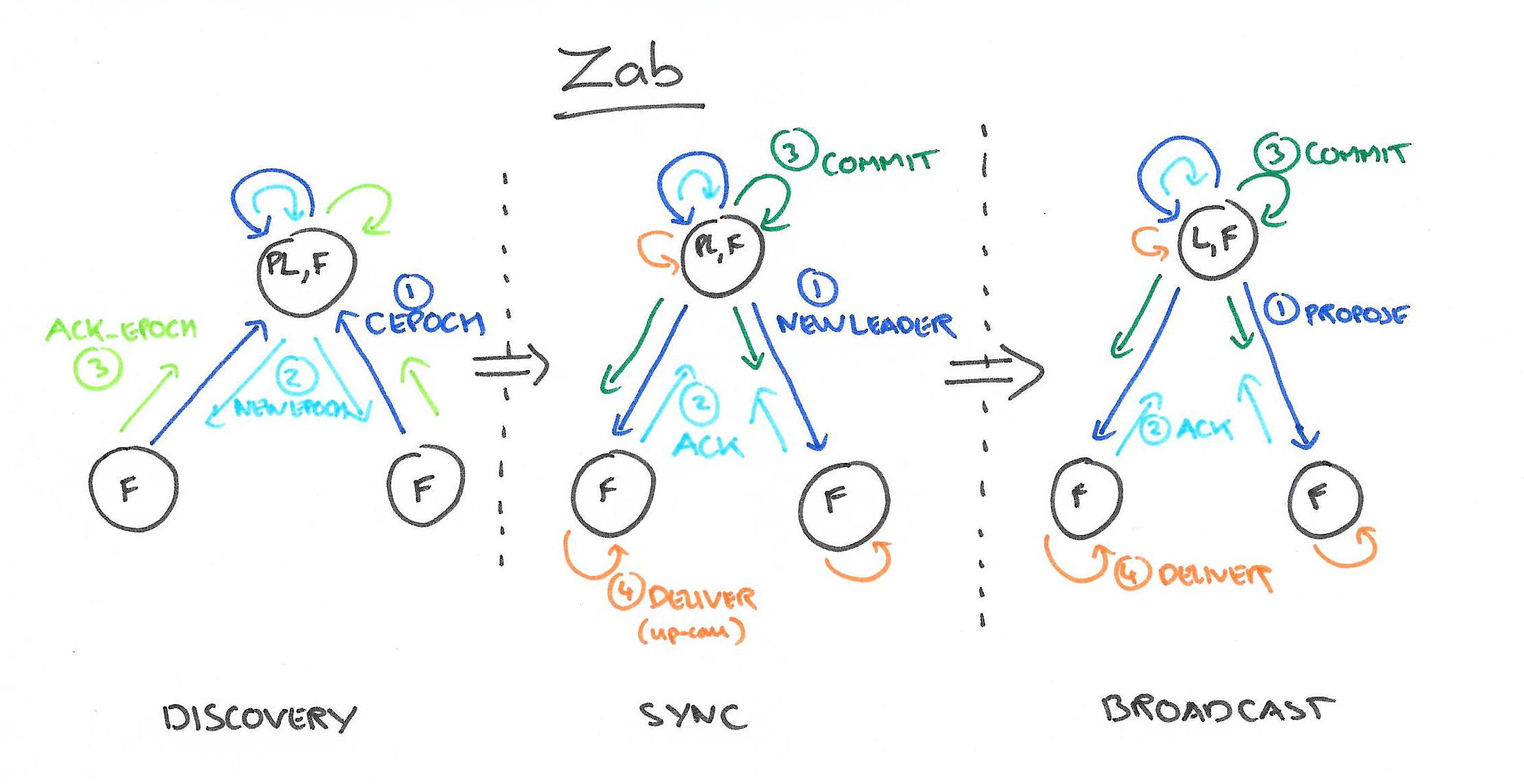
discovery: 选举产生PL(prospective leader),PL收集Follower epoch(cepoch),根据Follower的反馈PL产生newepoch(每次选举产生新Leader的同时产生新epoch,类似Raft的term)
sync: PL补齐相比Follower多数派缺失的状态、之后各Follower再补齐相比PL缺失的状态,PL和Follower完成状态同步后PL变为正式Leader(established leader)
broadcast: Leader处理Client的写操作,并将状态变更广播至Follower,Follower多数派通过之后Leader发起将状态变更落地(deliver/commit)
Raft:
单个 Candidate 的竞选
有三种节点:Follower、Candidate 和 Leader。Leader 会周期性的发送心跳包给 Follower。每个 Follower 都设置了一个随机的竞选超时时间,一般为 150ms~300ms,如果在这个时间内没有收到 Leader 的心跳包,就会变成 Candidate,进入竞选阶段。
- 下图表示一个分布式系统的最初阶段,此时只有 Follower,没有 Leader。Follower A 等待一个随机的竞选超时时间之后,没收到 Leader 发来的心跳包,因此进入竞选阶段。

- 此时 A 发送投票请求给其它所有节点。

- 其它节点会对请求进行回复,如果超过一半的节点回复了,那么该 Candidate 就会变成 Leader。

- 之后 Leader 会周期性地发送心跳包给 Follower,Follower 接收到心跳包,会重新开始计时。

多个 Candidate 竞选
- 如果有多个 Follower 成为 Candidate,并且所获得票数相同,那么就需要重新开始投票,例如下图中 Candidate B 和 Candidate D 都获得两票,因此需要重新开始投票。

- 当重新开始投票时,由于每个节点设置的随机竞选超时时间不同,因此能下一次再次出现多个 Candidate 并获得同样票数的概率很低。

日志复制
- 来自客户端的修改都会被传入 Leader。注意该修改还未被提交,只是写入日志中。

- Leader 会把修改复制到所有 Follower。

- Leader 会等待大多数的 Follower 也进行了修改,然后才将修改提交。

- 此时 Leader 会通知的所有 Follower 让它们也提交修改,此时所有节点的值达成一致。

zookeeper
zookeeper在分布式系统中作为协调员的角色,可应用于Leader选举、分布式锁、配置管理等服务的实现。以下我们从zookeeper供的API、应用场景和监控三方面学习和了解zookeeper(以下简称ZK)。
ZK API
ZK以Unix文件系统树结构的形式管理存储的数据,图示如下:
其中每个树节点被称为znode,每个znode类似一个文件,包含文件元信息(meta data)和数据。
以下我们用server表示ZK服务的提供方,client表示ZK服务的使用方,当client连接ZK时,相应创建session会话信息。
有两种类型的znode:
Regular: 该类型znode只能由client端显式创建或删除
Ephemeral: client端可创建或删除该类型znode;当session终止时,ZK亦会删除该类型znode
znode创建时还可以被打上sequential标志,被打上该标志的znode,将自行加上自增的数字后缀
ZK提供了以下API,供client操作znode和znode中存储的数据:
create(path, data, flags):创建路径为path的znode,在其中存储data[]数据,flags可设置为Regular或Ephemeral,并可选打上sequential标志。
delete(path, version):删除相应path/version的znode
exists(path,watch):如果存在path对应znode,则返回true;否则返回false,watch标志可设置监听事件
getData(path, watch):返回对应znode的数据和元信息(如version等)
setData(path, data, version):将data[]数据写入对应path/version的znode
getChildren(path, watch):返回指定znode的子节点集合K应用场景
基于以上ZK提供的znode和znode数据的操作,可轻松实现Leader选举、分布式锁、配置管理等服务。
Leader选举
利用打上sequential标志的Ephemeral,我们可以实现Leader选举。假设需要从三个client中选取Leader,实现过程如下:
1、各自创建Ephemeral类型的znode,并打上sequential标志:
[zk: localhost:2181(CONNECTED) 4] ls /master
[lock-0000000241, lock-0000000243, lock-0000000242]2、检查 /master 路径下的所有znode,如果自己创建的znode序号最小,则认为自己是Leader;否则记录序号比自己次小的znode
3、非Leader在次小序号znode上设置监听事件,并重复执行以上步骤2
配置管理
znode可以存储数据,基于这一点,我们可以用ZK实现分布式系统的配置管理,假设有服务A,A扩容设备时需要将相应新增的ip/port同步到全网服务器的A.conf配置,实现过程如下:
1、A扩容时,相应在ZK上新增znode,该znode数据形式如下:
[zk: localhost:2181(CONNECTED) 30] get /A/blk-0000340369
{“svr_info”: [{“ip”: “1.1.1.1.”, “port”: “11000”}]}
cZxid = 0x2ffdeda3be
……2、全网机器监听 /A,当该znode下有新节点加入时,调用相应处理函数,将服务A的新增ip/port加入A.conf
3、完成步骤2后,继续设置对 /A监听
ZK监控
ZK自身提供了一些“四字命令”,通过这些四字命令,我们可以获得ZK集群中,某台ZK的角色、znode数、健康状态等信息:
小结
zookeeper以目录树的形式管理数据,提供znode监听、数据设置等接口,基于这些接口,我们可以实现Leader选举、配置管理、命名服务等功能。结合四字命令,加上模拟zookeeper client 创建/删除znode,我们可以实现对zookeeper的有效监控。在各种分布式系统中,我们经常可以看到zookeeper的身影。
微信公众号
个人公众号:程序员黄小斜
微信公众号【程序员黄小斜】新生代青年聚集地,程序员成长充电站。作者黄小斜,职业是阿里程序员,身份是斜杠青年,希望和更多的程序员交朋友,一起进步和成长!这一次,我们一起出发。
关注公众号后回复“2019”领取我这两年整理的学习资料,涵盖自学编程、求职面试、算法刷题、Java技术、计算机基础和考研等8000G资料合集。

技术公众号:Java技术江湖
微信公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,专注于 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
关注公众号后回复“PDF”即可领取200+页的《Java工程师面试指南》强烈推荐,几乎涵盖所有Java工程师必知必会的知识点。


