这篇总结主要是基于我之前Hadoop生态基础系列文章而形成的的。主要是把重要的知识点用自己的话说了一遍,可能会有一些错误,还望见谅和指点。谢谢
更多详细内容可以查看我的专栏文章:Hadoop生态学习
https://blog.csdn.net/a724888/article/category/7779280
Hadoop生态
hdfs
架构
hdfs是一个分布式文件系统。底层的存储采用廉价的磁盘阵列RAID,由于可以并发读写所以效率很高。
基本架构是一个namenode和多个dataNode。node的意思是节点,一般指主机,也可以是虚拟机。
每个文件都会有两个副本存放在datanode中。
读写
客户端写入文件时,先把请求发送到namenode,namenode会返回datanode的服务地址,接着客户端去访问datanode,进行文件写入,然后通知namenode,namenode接收到写入完成的消息以后,会另外选两个datanode存放冗余副本。
读取文件时,从namenode获取一个datanode的地址,然后自己去读取即可。
当一个文件的副本不足两份时,namenode自动会完成副本复制。并且,由于datanode一般会放在各个机架。namenode一般会把副本一个放在同一机架,一个放在其他机架,防止某个机架出问题导致整个文件读写不可用。
高可用
namenode节点是单点,所以宕机了就没救了,所以我们可以使用zookeeper来保证namenode的高可用。可以使用zookeeper选主来实现故障切换,namenode先注册一个节点在zk上,表示自己是主,宕机时zk会通知备份节点进行切换。
Hadoop2.0中加入了hdfs namenode高可用的方案,也叫HDFS HA。namenode和一个备份节点绑定在一起,并且通过一个共享数据区域进行数据同步。同时支持故障切换。
MapReduce
架构和流程
MapReduce是基于Hadoop集群的分布式计算方案。一般先编写map函数进行数据分片,然后通过shuffle进行相同分片的整合,最后通过reduce把所有的数据结果进行整理。
具体来说,用户提交一个MapReduce程序给namenode节点,namenode节点启动一个jobtracker进行子任务的调度和监控,然后派发每个子任务tasktracker到datanode进行任务执行,由于数据分布在各个节点,每个tasktracker只需要执行自己的那一部分即可。最后再将结果汇总给tasktracker。
wordcount
首先是一个文本文件:hi hello good hello hi hi。
三个节点,则进行三次map。hi hello,good hello,hi hi分别由三个节点处理。结果分别是hi 1 hello 1,good 1 hello 1,hi 1,hi 1。
shuffle时进行combine操作,得到hi 1,hello 1,good 1 hello 1,hi 2。最终reduce的结果是hi 3 hello 2 good 1.
hive
hive是一个基于hdfs文件系统的数据仓库。可以通过hive sql语句执行对hdfs上文件的数据查询。原理是hive把hdfs上的数据文件看成一张张数据表,把表结构信息存在关系数据库如mysql中。然后执行sql时通过对表结构的解析再去hdfs上查询真正的数据,最后也会以结构化的形式返回。
hbase
简介
hbase是基于列的数据库。
他与传统关系数据库有很大不同。
首先在表结构上,hbase使用rowkey行键作为唯一主键,通过行键唯一确定一行数据。
同时,hbase使用列族的概念,每个表都有固定的列族,每一行的数据的列族都一样,但是每一行所在列族的实际列都可以不一样。
比如列族是info,列可以是name age,也可以是sex address等。也就是说具体列可以在插入数据时再进行确认。
并且,hbase的每一行数据还可以有多个版本,通过时间戳来表示不同的数据版本。
存储
一般情况下hbase使用hdfs作为底层存储,所以hdfs提供了数据的可靠性以及并发读写的高效率。
hbase一个表的 每n行数据会存在一个region中,并且,对于列来说,每一个列族都会用一个region来存储,假设有m个列族,那么就会有n * m个region需要存储在hdfs上。
同时hbase使用regionserver来管理这些region,他们可能存在不同的datanode里,所以通过regionserver可以找出每一个region的位置。
hbase使用zookeeper来保证regionserver的高可用,会自动进行故障切换。
zk
zk在Hadoop的作用有几个,通过选主等机制保证主节点高可用。
使用zk进行配置资源的统一管理,保证服务器节点无状态,所有服务信息直接从zk获取即可。
使用zookeeper进行节点间的通信等,也可以使用zk的目录顺序节点实现分布式锁,以及服务器选主。不仅在Hadoop中,zk在分布式系统中总能有用武之地。
zookeeper本身的部署方式就是一个集群,一个master和多个slave。
使用zab协议保证一致性和高可用。
zab协议实现原理:
1 使用两段式提交的方式确保一个协议需要半数以上节点同意以后再进行广播执行。
2 使用基于机器编号加时间戳的id来表示每个事务,通过这个方式当初始选举或者主节点宕机时进行一轮选主,每个节点优先选择自己当主节点,在选举过程中节点优先采纳比较新的事务,将自己的选票更新,然后反馈个其他机器,最后当一个机器获得超过半数选票时当选为master。
3选主结束以后,主节点与slave进行主从同步,保证数据一致性,然后对外提供服务,并且写入只能通过master而读取可以通过任意一台机器。
sqoop
将hive表中的内容导入到MySQL数据库,也可以将MySQL中的数据导入hive中。
yarn
没有yarn之前,hdfs使用jobtracker和tasktracker来执行和跟踪任务,jobtracker的任务太重,又要执行又要监控还要获取结果。
并且不同机器的资源情况没有被考虑在内。
yarn是一个资源调度系统。提供applicationmaster对一个调度任务进行封装,然后有一个resourcemanager专门负责各节点资源的管理和监控。同时nodemanager则运行每个节点中用于监控节点状态和向rm汇报。还有一个container则是对节点资源的一个抽象,applicationmaster任务将由节点上的一个container进行执行。rm会将他调度到最合适的机器上。
kafka
架构
kafka是一个分布式的消息队列。
它组成一般包括kafka broker,每个broker中有多个的partition作为存储消息的队列。
并且向上提供服务时抽象为一个topic,我们访问topic时实际上执行的是对partition的写入和读取操作。
读写和高可用
partition支持顺序写入,效率比较高,并且支持零拷贝机制,通过内存映射磁盘mmap的方式,写入partition的数据顺序写入到映射的磁盘中,比传统的IO要快。
由于partition可能会宕机,所以一般也要支持partition的备份,1个broker ,master通常会有多个
broker slave,是主从关系,通过zookeeper进行选主和故障切换。当数据写入队列时,一般也会通过日志文件的方式进行数据备份,会把broker中的partition被分在各个slave中以便于均匀分布和恢复。
生产者和消费者
生产者消费者需要访问kafka的队列时,如果是写入,直接向zk发送请求,一般是向一个topic写入消息,broker会自动分配partition进行写入。然后zk会告诉生产者写入的partition所在的broker地址,然后进行写入。
如果是读取的话,也是通过zk获取partition所在位置,然后通过给定的offset进行读取,读取完后更新offset。
由于kafka的partition支持顺序读写。所以保证一个partition中的读取和写入时是顺序的,但是如果是多个partition则不保证顺序。
正常情况下kafka使用topic来实现消息点对点发送,并且每个consumer都要在一个consumer group中,而且comsumer group中每次只能有一个消费者能接受对应topic的消息。因为为了实现订阅也就是一对多发送,我们让每个consumer在一个单独的group,于是每个consumer都可以接受到该消息。
flume
flume用于数据的收集和分发,flume可以监听端口的数据流入,监视文件的变动以及各种数据形式的数据流入,然后再把数据重新转发到其他需要数据的节点或存储中。
1、Flume的概念
flume是分布式的日志收集系统,它将各个服务器中的数据收集起来并送到指定的地方去,比如说送到图中的HDFS,简单来说flume就是收集日志的。
2、Event的概念
在这里有必要先介绍一下flume中event的相关概念:flume的核心是把数据从数据源(source)收集过来,在将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume在删除自己缓存的数据。
在整个数据的传输的过程中,流动的是event,即事务保证是在event级别进行的。那么什么是event呢?—–event将传输的数据进行封装,是flume传输数据的基本单位,如果是文本文件,通常是一行记录,event也是事务的基本单位。event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。
flume使用
ambari
ambari就是一个Hadoop的Web应用。
spark
spark和MapReduce不同的地方就是,把计算过程放在内存中运行。
spark提出了抽象的RDD分布式内存模型,把每一步的计算操作转换成一个RDD结构,然后形成一个RDD连接而成的有向图。
比如data.map().filter().reduce();
程序提交到master以后,会解析成多个RDD,并且形成一个有向图,然后spark再根据这些RD结构在内存中执行对应的操作。当然这个拓扑结构会被拆分为各个子任务分发到各个spark节点上,然后计算完以后再形成下一个rdd。最后汇总结果即可。
由于是在内存中对数据进行操作,省去了不必要的IO操作,,不需要像Mapreduce一样还得先去hdfs读取文件再完成计算。
storm
在运行一个Storm任务之前,需要了解一些概念:
- Topologies
- Streams
- Spouts
- Bolts
- Stream groupings
- Reliability
- Tasks
- Workers
- Configuration
Storm集群和Hadoop集群表面上看很类似。但是Hadoop上运行的是MapReduce jobs,而在Storm上运行的是拓扑(topology),这两者之间是非常不一样的。一个关键的区别是: 一个MapReduce job最终会结束, 而一个topology永远会运行(除非你手动kill掉)。
在Storm的集群里面有两种节点: 控制节点(master node)和工作节点(worker node)。控制节点上面运行一个叫Nimbus后台程序,它的作用类似Hadoop里面的JobTracker。Nimbus负责在集群里面分发代码,分配计算任务给机器, 并且监控状态。
每一个工作节点上面运行一个叫做Supervisor的节点。Supervisor会监听分配给它那台机器的工作,根据需要启动/关闭工作进程。每一个工作进程执行一个topology的一个子集;一个运行的topology由运行在很多机器上的很多工作进程组成。
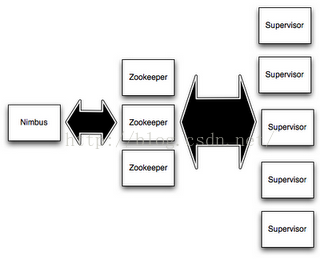
Nimbus和Supervisor之间的所有协调工作都是通过Zookeeper集群完成。另外,Nimbus进程和Supervisor进程都是快速失败(fail-fast)和无状态的。所有的状态要么在zookeeper里面, 要么在本地磁盘上。这也就意味着你可以用kill -9来杀死Nimbus和Supervisor进程, 然后再重启它们,就好像什么都没有发生过。这个设计使得Storm异常的稳定。
storm比起spark它的实时性能更高更强,storm可以做到亚秒级别的数据输入分析。而spark的方式是通过秒级的数据切分,来形成spark rdd数据集,然后再按照DAG有向图进行执行的。
storm则不然。
一:介绍Storm设计模型
1.Topology
Storm对任务的抽象,其实 就是将实时数据分析任务 分解为 不同的阶段
点: 计算组件 Spout Bolt
边: 数据流向 数据从上一个组件流向下一个组件 带方向
2.tuple
Storm每条记录 封装成一个tuple
其实就是一些keyvalue对按顺序排列
方便组件获取数据
3.Spout
数据采集器
源源不断的日志记录 如何被topology接收进行处理?
Spout负责从数据源上获取数据,简单处理 封装成tuple向后面的bolt发射
4.Bolt
数据处理器
二:开发wordcount案例
1.书写整个大纲的点线图

topology就是一个拓扑图,类似于spark中的dag有向图,只不过storm执行的流式的数据,比dag执行更加具有实时性。
topology包含了spout和bolt。
spout负责获取数据,并且将数据发送给bolt,这个过程就是把任务派发到多个节点,bolt则负责对数据进行处理,比如splitbolt负责把每个单词提取出来,countbolt负责单词数量的统计,最后的printbolt将每个结果集tuple打印出来。
这就形成了一个完整的流程。
微信公众号
个人公众号:程序员黄小斜
微信公众号【程序员黄小斜】新生代青年聚集地,程序员成长充电站。作者黄小斜,职业是阿里程序员,身份是斜杠青年,希望和更多的程序员交朋友,一起进步和成长!这一次,我们一起出发。
关注公众号后回复“2019”领取我这两年整理的学习资料,涵盖自学编程、求职面试、算法刷题、Java技术、计算机基础和考研等8000G资料合集。

技术公众号:Java技术江湖
微信公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,专注于 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
关注公众号后回复“PDF”即可领取200+页的《Java工程师面试指南》强烈推荐,几乎涵盖所有Java工程师必知必会的知识点。


