本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
喜欢的话麻烦点下Star哈
文章首发于我的微信公众号【黄小斜】,也会同步到我的个人博客:
如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
喜欢的话麻烦点下Star哈
文章首发于我的微信公众号【黄小斜】,也会同步到我的个人博客:
如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
作者:[木东居士]
个人主页:http://www.mdjs.info
也可以关注我:木东居士。
文章可以转载, 但必须以超链接形式标明文章原始出处和作者信息
你了解你的数据吗?
前几天突然来了点灵感,想梳理一下自己对数据的理解,因此便有了这篇博客或者说这系列博客来聊聊数据。
数据从业者有很多,比如说数据开发工程师、数据仓库工程师、数据分析师、数据挖掘工程师、数据产品经理等等,不同岗位的童鞋对数据的理解有很大的不一样,而且侧重点也不同。那么,是否有一些数据相关的基础知识是所有数据从业者都值得了解的?不同的岗位对数据的理解又有多大的不同?数据开发工程师是否有必要去了解数据分析师是如何看待数据的?
本系列博客会尝试去学习、挖掘和总结这些内容,在数据的海洋中一起装x一起飞。
开篇先上几个问题:
如果你对前面说的问题有不太了解的,那么我们就可以在以后的内容中一起愉快地交流和探讨。如果前面说的问题你的回答都是 “Yes”,那么我还是会尝试用新的问题来留住你。比如说:
假设你对上面的问题有稍许困惑或者感兴趣,我们正式开始对数据的认知之旅。
现在,我们粗略地将数据从业者分为数据集群运维、数据开发工程师、数据仓库工程师、数据分析师、数据挖掘工程师和数据产品经理,这一小节先起一个引子来大致说明不同岗位对数据的了解是不同的,后文会详细地说明细节内容。
首先要说明的是,在工作中数据相关的职位都是有很多重合的,很难一刀切区分不同岗位的职责,比如说数据开发工程师本身就是一个很大的概念,他可以做数据接入、数据清洗、数据仓库开发、数据挖掘算法开发等等,再比如说数据分析师,很多数据分析师既要做数据分析,又要做一些提数的需求,有时候还要自己做各种处理。
公司的数据团队越大,相应的岗位职责就会越细分,反之亦然。在这里我们姑且用数据开发工程师和数据仓库工程师做对比来说明不同职责的同学对数据理解的侧重点有什么不同。我们假设数据开发工程师侧重于数据的接入、存储和基本的数据处理,数据仓库工程师侧重于数据模型的设计和开发(比如维度建模)。
数据开发工程师对数据最基本的了解是需要知道数据的接入状态,比如说每天总共接入多少数据,整体数据量是多大,接入的业务有多少,每个业务的接入量多大,多大波动范围是正常?然后还要对数据的存储周期有一个把握,比如说有多少表的存储周期是30天,有多少是90天?集群每日新增的存储量是多大,多久后集群存储会撑爆?
数据仓库工程师对上面的内容也要有一定的感知力,但是会有所区别,比如说,数据仓库工程师会更关注自己仓库建模中用到业务的数据状态。然后还需要知道终点业务的数据分布,比如说用户表中的年龄分布、性别分布、地域分布等。除此之外还应关注数据口径问题,比如说有很多份用户资料表,每张表的性别取值是否都是:男、女、未知,还是说会有用数值类型:1男、2女、0未知。
然后数据开发工程师对数据异常的侧重点可能会在今天的数据是否延迟落地,总量是否波动很大,数据可用率是否正常。
数据仓库工程师对数据异常的侧重点则可能是,今天落地的数据中性别为 0 的数据量是否激增(这可能会造成数据倾斜),某一个关键维度取值是否都为空。
上面的例子可能都会在一个数据质量监控系统中一起解决,但是我们在这里不讨论系统的设计,而是先有整体的意识和思路。
那么,后续博客的内容会是什么样子的呢?目前来看,我认为会有两个角度:
本篇主要是抛出一些问题,后续会逐步展开地细说数据从业者对数据理解。其实最开始我想用“数据敏感度”、“数据感知力”这类标题,但是感觉这种概念比较难定义,因此用了比较口语化的标题。
笔者认为,在数据从业者的职业生涯中,不应只有编程、算法和系统,还应有一套数据相关的方法论,这套方法论会来解决某一领域的问题,即使你们的系统从Hadoop换到了Spark,数据模型从基本的策略匹配换到了深度学习,这些方法论也依旧会伴你整个职业生涯。因此这系列博客会尝试去学习、挖掘和总结一套这样的方法论,与君共勉。
微信公众号【程序员黄小斜】新生代青年聚集地,程序员成长充电站。作者黄小斜,职业是阿里程序员,身份是斜杠青年,希望和更多的程序员交朋友,一起进步和成长!这一次,我们一起出发。
关注公众号后回复“2019”领取我这两年整理的学习资料,涵盖自学编程、求职面试、算法刷题、Java技术、计算机基础和考研等8000G资料合集。

微信公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,专注于 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
关注公众号后回复“PDF”即可领取200+页的《Java工程师面试指南》强烈推荐,几乎涵盖所有Java工程师必知必会的知识点。

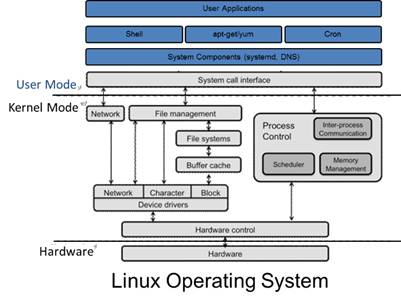
要搞懂docker的核心原理和技术,首先一定要对Linux内核有一定了解。
提到虚拟化技术,我们首先想到的一定是 Docker,经过四年的快速发展 Docker 已经成为了很多公司的标配,也不再是一个只能在开发阶段使用的玩具了。作为在生产环境中广泛应用的产品,Docker 有着非常成熟的社区以及大量的使用者,代码库中的内容也变得非常庞大。
![]()
同样,由于项目的发展、功能的拆分以及各种奇怪的改名 PR,让我们再次理解 Docker 的的整体架构变得更加困难。
虽然 Docker 目前的组件较多,并且实现也非常复杂,但是本文不想过多的介绍 Docker 具体的实现细节,我们更想谈一谈 Docker 这种虚拟化技术的出现有哪些核心技术的支撑。

首先,Docker 的出现一定是因为目前的后端在开发和运维阶段确实需要一种虚拟化技术解决开发环境和生产环境环境一致的问题,通过 Docker 我们可以将程序运行的环境也纳入到版本控制中,排除因为环境造成不同运行结果的可能。但是上述需求虽然推动了虚拟化技术的产生,但是如果没有合适的底层技术支撑,那么我们仍然得不到一个完美的产品。本文剩下的内容会介绍几种 Docker 使用的核心技术,如果我们了解它们的使用方法和原理,就能清楚 Docker 的实现原理。
命名空间 (namespaces) 是 Linux 为我们提供的用于分离进程树、网络接口、挂载点以及进程间通信等资源的方法。在日常使用 Linux 或者 macOS 时,我们并没有运行多个完全分离的服务器的需要,但是如果我们在服务器上启动了多个服务,这些服务其实会相互影响的,每一个服务都能看到其他服务的进程,也可以访问宿主机器上的任意文件,这是很多时候我们都不愿意看到的,我们更希望运行在同一台机器上的不同服务能做到完全隔离,就像运行在多台不同的机器上一样。
在这种情况下,一旦服务器上的某一个服务被入侵,那么入侵者就能够访问当前机器上的所有服务和文件,这也是我们不想看到的,而 Docker 其实就通过 Linux 的 Namespaces 对不同的容器实现了隔离。
Linux 的命名空间机制提供了以下七种不同的命名空间,包括 CLONE_NEWCGROUP、CLONE_NEWIPC、CLONE_NEWNET、CLONE_NEWNS、CLONE_NEWPID、CLONE_NEWUSER 和 CLONE_NEWUTS,通过这七个选项我们能在创建新的进程时设置新进程应该在哪些资源上与宿主机器进行隔离。
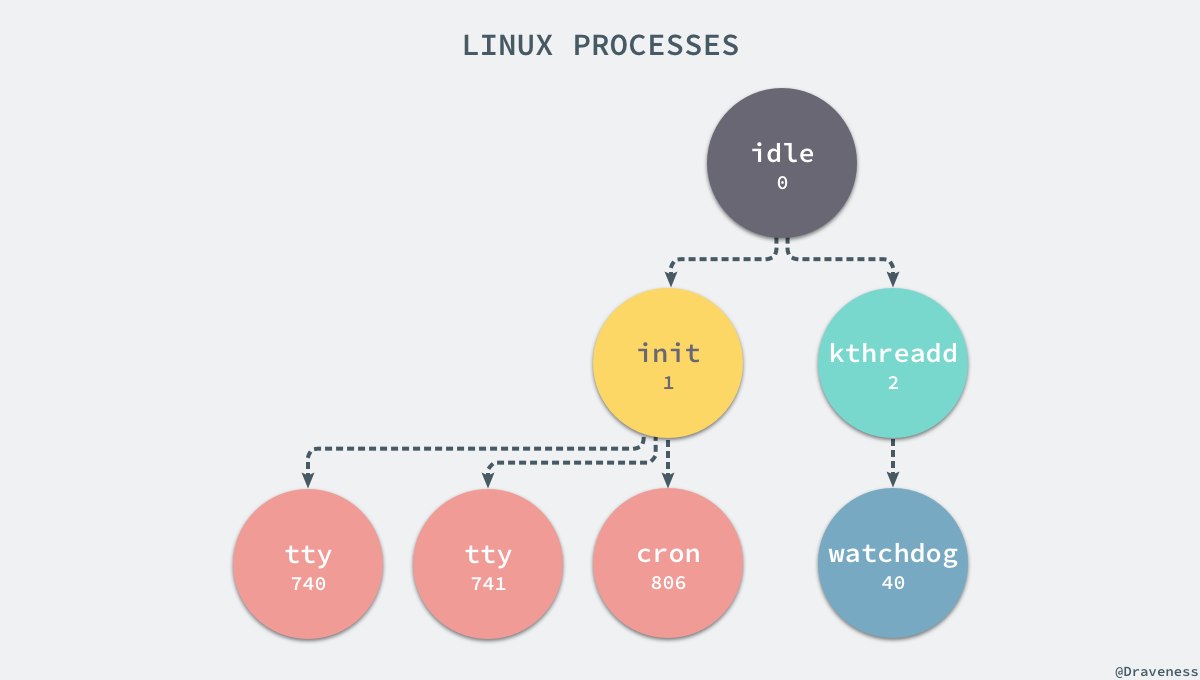
进程是 Linux 以及现在操作系统中非常重要的概念,它表示一个正在执行的程序,也是在现代分时系统中的一个任务单元。在每一个 *nix 的操作系统上,我们都能够通过 ps 命令打印出当前操作系统中正在执行的进程,比如在 Ubuntu 上,使用该命令就能得到以下的结果:
1 | $ ps -efUID PID PPID C STIME TTY TIME CMDroot 1 0 0 Apr08 ? 00:00:09 /sbin/initroot 2 0 0 Apr08 ? 00:00:00 [kthreadd]root 3 2 0 Apr08 ? 00:00:05 [ksoftirqd/0]root 5 2 0 Apr08 ? 00:00:00 [kworker/0:0H]root 7 2 0 Apr08 ? 00:07:10 [rcu_sched]root 39 2 0 Apr08 ? 00:00:00 [migration/0]root 40 2 0 Apr08 ? 00:01:54 [watchdog/0]... |
当前机器上有很多的进程正在执行,在上述进程中有两个非常特殊,一个是 pid 为 1 的 /sbin/init 进程,另一个是 pid 为 2 的 kthreadd 进程,这两个进程都是被 Linux 中的上帝进程 idle 创建出来的,其中前者负责执行内核的一部分初始化工作和系统配置,也会创建一些类似 getty 的注册进程,而后者负责管理和调度其他的内核进程。
如果我们在当前的 Linux 操作系统下运行一个新的 Docker 容器,并通过 exec 进入其内部的 bash 并打印其中的全部进程,我们会得到以下的结果:
1 | root@iZ255w13cy6Z:~# docker run -it -d ubuntub809a2eb3630e64c581561b08ac46154878ff1c61c6519848b4a29d412215e79root@iZ255w13cy6Z:~# docker exec -it b809a2eb3630 /bin/bashroot@b809a2eb3630:/# ps -efUID PID PPID C STIME TTY TIME CMDroot 1 0 0 15:42 pts/0 00:00:00 /bin/bashroot 9 0 0 15:42 pts/1 00:00:00 /bin/bashroot 17 9 0 15:43 pts/1 00:00:00 ps -ef |
在新的容器内部执行 ps 命令打印出了非常干净的进程列表,只有包含当前 ps -ef 在内的三个进程,在宿主机器上的几十个进程都已经消失不见了。
当前的 Docker 容器成功将容器内的进程与宿主机器中的进程隔离,如果我们在宿主机器上打印当前的全部进程时,会得到下面三条与 Docker 相关的结果:
1 | UID PID PPID C STIME TTY TIME CMDroot 29407 1 0 Nov16 ? 00:08:38 /usr/bin/dockerd --raw-logsroot 1554 29407 0 Nov19 ? 00:03:28 docker-containerd -l unix:///var/run/docker/libcontainerd/docker-containerd.sock --metrics-interval=0 --start-timeout 2m --state-dir /var/run/docker/libcontainerd/containerd --shim docker-containerd-shim --runtime docker-runcroot 5006 1554 0 08:38 ? 00:00:00 docker-containerd-shim b809a2eb3630e64c581561b08ac46154878ff1c61c6519848b4a29d412215e79 /var/run/docker/libcontainerd/b809a2eb3630e64c581561b08ac46154878ff1c61c6519848b4a29d412215e79 docker-runc |
在当前的宿主机器上,可能就存在由上述的不同进程构成的进程树:
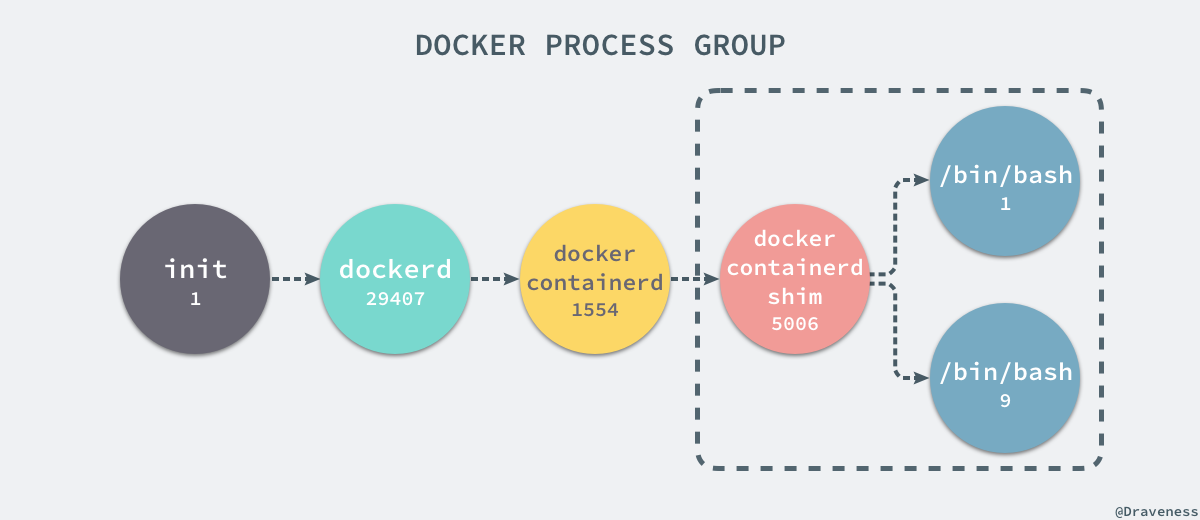
这就是在使用 clone(2) 创建新进程时传入 CLONE_NEWPID 实现的,也就是使用 Linux 的命名空间实现进程的隔离,Docker 容器内部的任意进程都对宿主机器的进程一无所知。
1 | containerRouter.postContainersStart└── daemon.ContainerStart └── daemon.createSpec └── setNamespaces └── setNamespace |
Docker 的容器就是使用上述技术实现与宿主机器的进程隔离,当我们每次运行 docker run 或者 docker start 时,都会在下面的方法中创建一个用于设置进程间隔离的 Spec:
1 | func (daemon *Daemon) createSpec(c *container.Container) (*specs.Spec, error) { s := oci.DefaultSpec() // ... if err := setNamespaces(daemon, &s, c); err != nil { return nil, fmt.Errorf("linux spec namespaces: %v", err) } return &s, nil} |
在 setNamespaces 方法中不仅会设置进程相关的命名空间,还会设置与用户、网络、IPC 以及 UTS 相关的命名空间:
1 | func setNamespaces(daemon *Daemon, s *specs.Spec, c *container.Container) error { // user // network // ipc // uts // pid if c.HostConfig.PidMode.IsContainer() { ns := specs.LinuxNamespace{Type: "pid"} pc, err := daemon.getPidContainer(c) if err != nil { return err } ns.Path = fmt.Sprintf("/proc/%d/ns/pid", pc.State.GetPID()) setNamespace(s, ns) } else if c.HostConfig.PidMode.IsHost() { oci.RemoveNamespace(s, specs.LinuxNamespaceType("pid")) } else { ns := specs.LinuxNamespace{Type: "pid"} setNamespace(s, ns) } return nil} |
所有命名空间相关的设置 Spec 最后都会作为 Create 函数的入参在创建新的容器时进行设置:
1 | daemon.containerd.Create(context.Background(), container.ID, spec, createOptions) |
所有与命名空间的相关的设置都是在上述的两个函数中完成的,Docker 通过命名空间成功完成了与宿主机进程和网络的隔离。
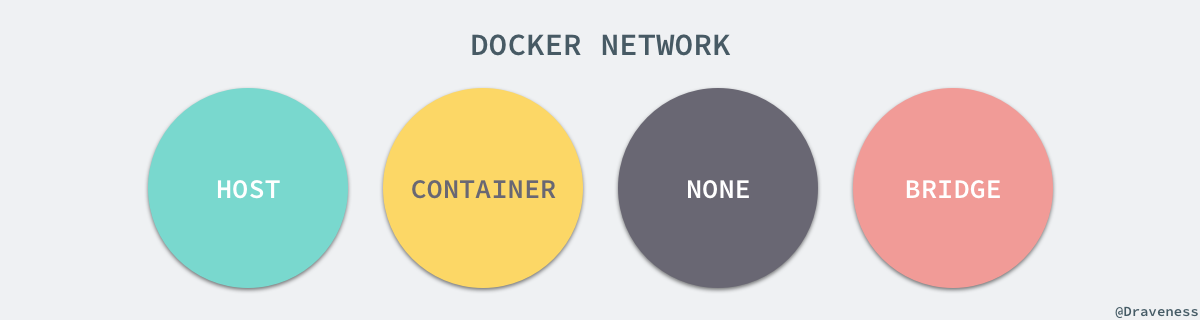
如果 Docker 的容器通过 Linux 的命名空间完成了与宿主机进程的网络隔离,但是却有没有办法通过宿主机的网络与整个互联网相连,就会产生很多限制,所以 Docker 虽然可以通过命名空间创建一个隔离的网络环境,但是 Docker 中的服务仍然需要与外界相连才能发挥作用。
每一个使用 docker run 启动的容器其实都具有单独的网络命名空间,Docker 为我们提供了四种不同的网络模式,Host、Container、None 和 Bridge 模式。
在这一部分,我们将介绍 Docker 默认的网络设置模式:网桥模式。在这种模式下,除了分配隔离的网络命名空间之外,Docker 还会为所有的容器设置 IP 地址。当 Docker 服务器在主机上启动之后会创建新的虚拟网桥 docker0,随后在该主机上启动的全部服务在默认情况下都与该网桥相连。
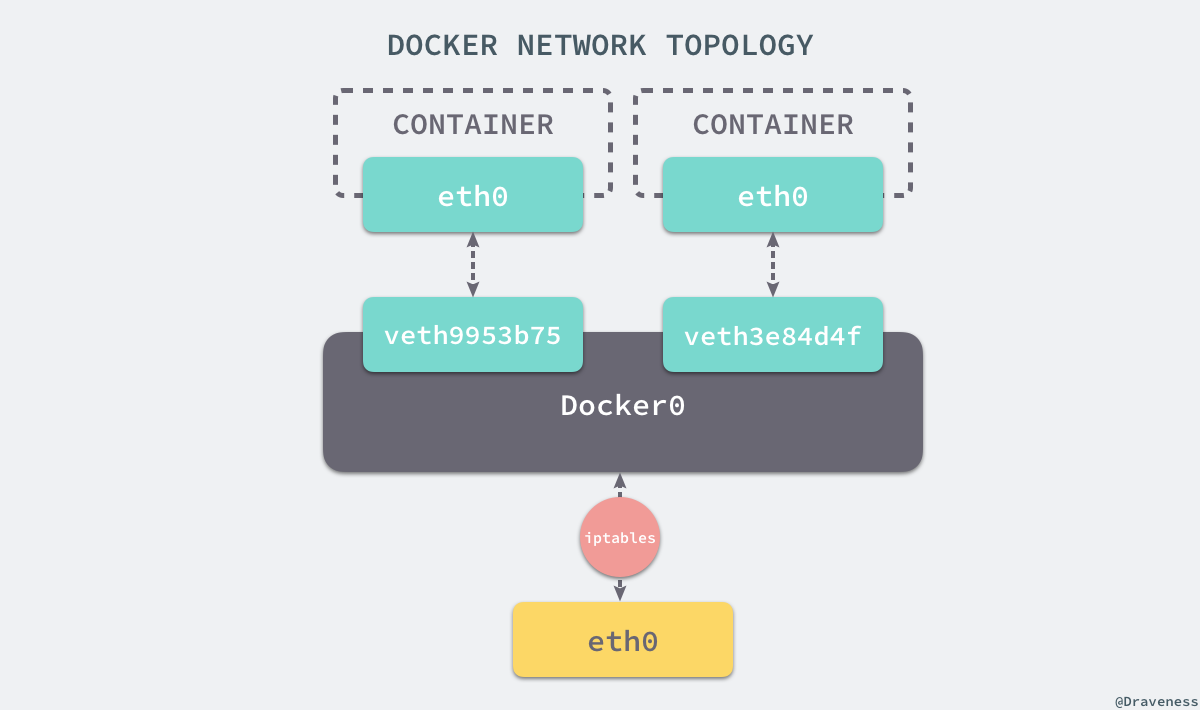
在默认情况下,每一个容器在创建时都会创建一对虚拟网卡,两个虚拟网卡组成了数据的通道,其中一个会放在创建的容器中,会加入到名为 docker0 网桥中。我们可以使用如下的命令来查看当前网桥的接口:
1 | $ brctl showbridge name bridge id STP enabled interfacesdocker0 8000.0242a6654980 no veth3e84d4f veth9953b75 |
docker0 会为每一个容器分配一个新的 IP 地址并将 docker0 的 IP 地址设置为默认的网关。网桥 docker0 通过 iptables 中的配置与宿主机器上的网卡相连,所有符合条件的请求都会通过 iptables 转发到 docker0 并由网桥分发给对应的机器。
1 | $ iptables -t nat -LChain PREROUTING (policy ACCEPT)target prot opt source destinationDOCKER all -- anywhere anywhere ADDRTYPE match dst-type LOCAL Chain DOCKER (2 references)target prot opt source destinationRETURN all -- anywhere anywhere |
我们在当前的机器上使用 docker run -d -p 6379:6379 redis 命令启动了一个新的 Redis 容器,在这之后我们再查看当前 iptables 的 NAT 配置就会看到在 DOCKER 的链中出现了一条新的规则:
1 | DNAT tcp -- anywhere anywhere tcp dpt:6379 to:192.168.0.4:6379 |
上述规则会将从任意源发送到当前机器 6379 端口的 TCP 包转发到 192.168.0.4:6379 所在的地址上。
这个地址其实也是 Docker 为 Redis 服务分配的 IP 地址,如果我们在当前机器上直接 ping 这个 IP 地址就会发现它是可以访问到的:
1 | $ ping 192.168.0.4PING 192.168.0.4 (192.168.0.4) 56(84) bytes of data.64 bytes from 192.168.0.4: icmp_seq=1 ttl=64 time=0.069 ms64 bytes from 192.168.0.4: icmp_seq=2 ttl=64 time=0.043 ms^C--- 192.168.0.4 ping statistics ---2 packets transmitted, 2 received, 0% packet loss, time 999msrtt min/avg/max/mdev = 0.043/0.056/0.069/0.013 ms |
从上述的一系列现象,我们就可以推测出 Docker 是如何将容器的内部的端口暴露出来并对数据包进行转发的了;当有 Docker 的容器需要将服务暴露给宿主机器,就会为容器分配一个 IP 地址,同时向 iptables 中追加一条新的规则。
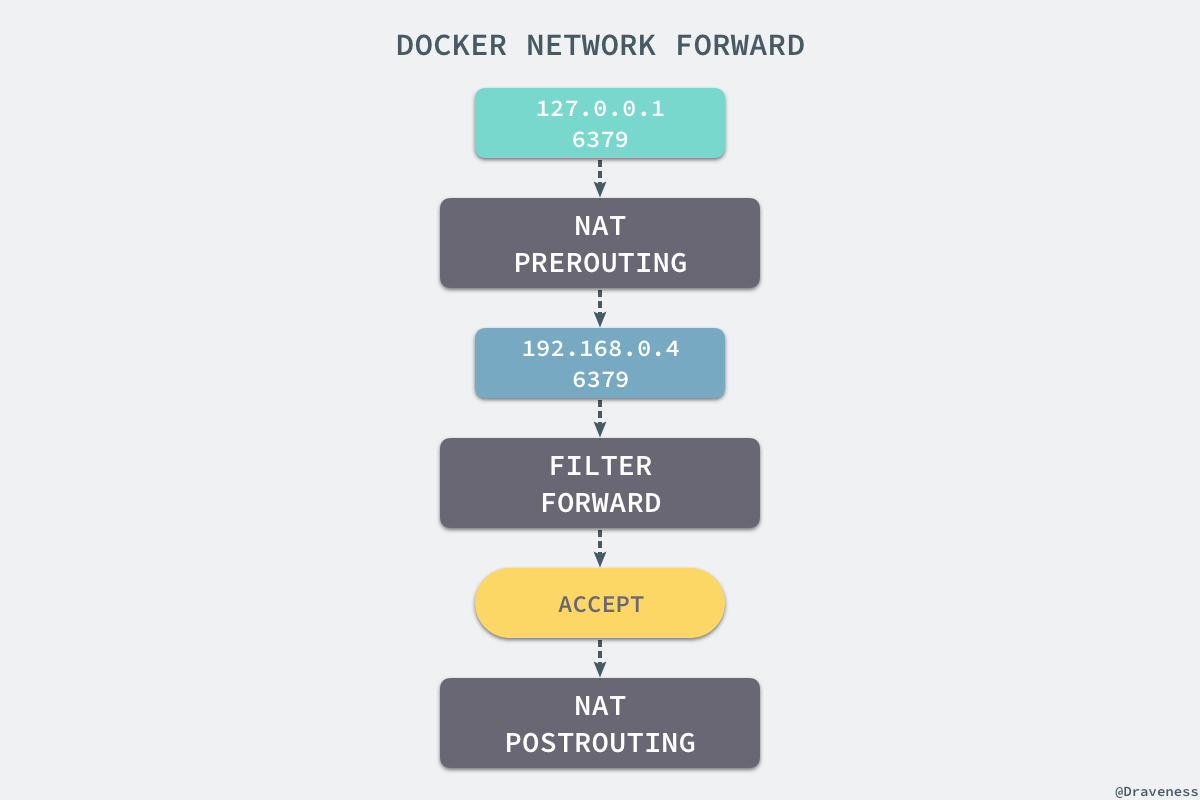
当我们使用 redis-cli 在宿主机器的命令行中访问 127.0.0.1:6379 的地址时,经过 iptables 的 NAT PREROUTING 将 ip 地址定向到了 192.168.0.4,重定向过的数据包就可以通过 iptables 中的 FILTER 配置,最终在 NAT POSTROUTING 阶段将 ip 地址伪装成 127.0.0.1,到这里虽然从外面看起来我们请求的是 127.0.0.1:6379,但是实际上请求的已经是 Docker 容器暴露出的端口了。
1 | $ redis-cli -h 127.0.0.1 -p 6379 pingPONG |
Docker 通过 Linux 的命名空间实现了网络的隔离,又通过 iptables 进行数据包转发,让 Docker 容器能够优雅地为宿主机器或者其他容器提供服务。
整个网络部分的功能都是通过 Docker 拆分出来的 libnetwork 实现的,它提供了一个连接不同容器的实现,同时也能够为应用给出一个能够提供一致的编程接口和网络层抽象的容器网络模型。
The goal of libnetwork is to deliver a robust Container Network Model that provides a consistent programming interface and the required network abstractions for applications.
libnetwork 中最重要的概念,容器网络模型由以下的几个主要组件组成,分别是 Sandbox、Endpoint 和 Network:
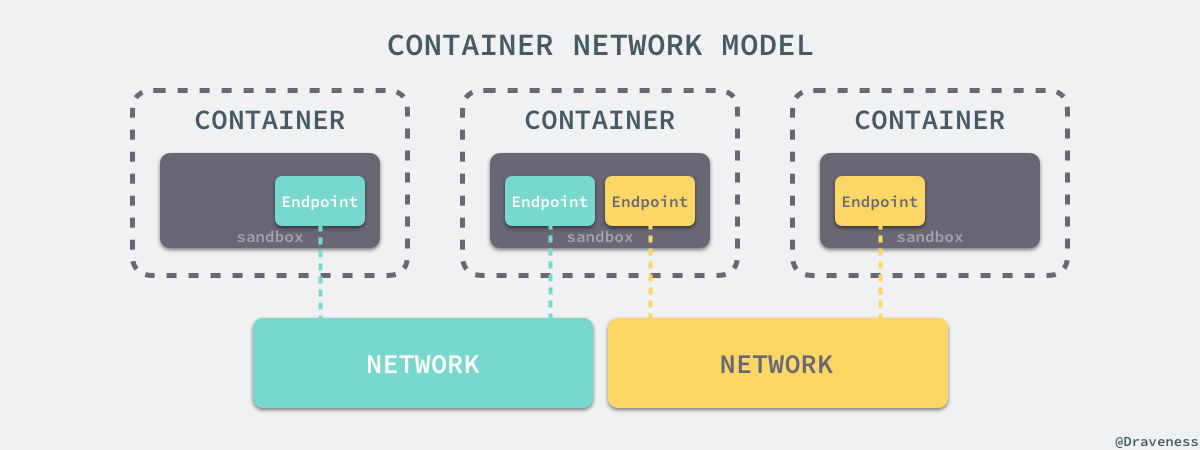
在容器网络模型中,每一个容器内部都包含一个 Sandbox,其中存储着当前容器的网络栈配置,包括容器的接口、路由表和 DNS 设置,Linux 使用网络命名空间实现这个 Sandbox,每一个 Sandbox 中都可能会有一个或多个 Endpoint,在 Linux 上就是一个虚拟的网卡 veth,Sandbox 通过 Endpoint 加入到对应的网络中,这里的网络可能就是我们在上面提到的 Linux 网桥或者 VLAN。
想要获得更多与 libnetwork 或者容器网络模型相关的信息,可以阅读 Design · libnetwork 了解更多信息,当然也可以阅读源代码了解不同 OS 对容器网络模型的不同实现。
虽然我们已经通过 Linux 的命名空间解决了进程和网络隔离的问题,在 Docker 进程中我们已经没有办法访问宿主机器上的其他进程并且限制了网络的访问,但是 Docker 容器中的进程仍然能够访问或者修改宿主机器上的其他目录,这是我们不希望看到的。
在新的进程中创建隔离的挂载点命名空间需要在 clone 函数中传入 CLONE_NEWNS,这样子进程就能得到父进程挂载点的拷贝,如果不传入这个参数子进程对文件系统的读写都会同步回父进程以及整个主机的文件系统。
如果一个容器需要启动,那么它一定需要提供一个根文件系统(rootfs),容器需要使用这个文件系统来创建一个新的进程,所有二进制的执行都必须在这个根文件系统中。
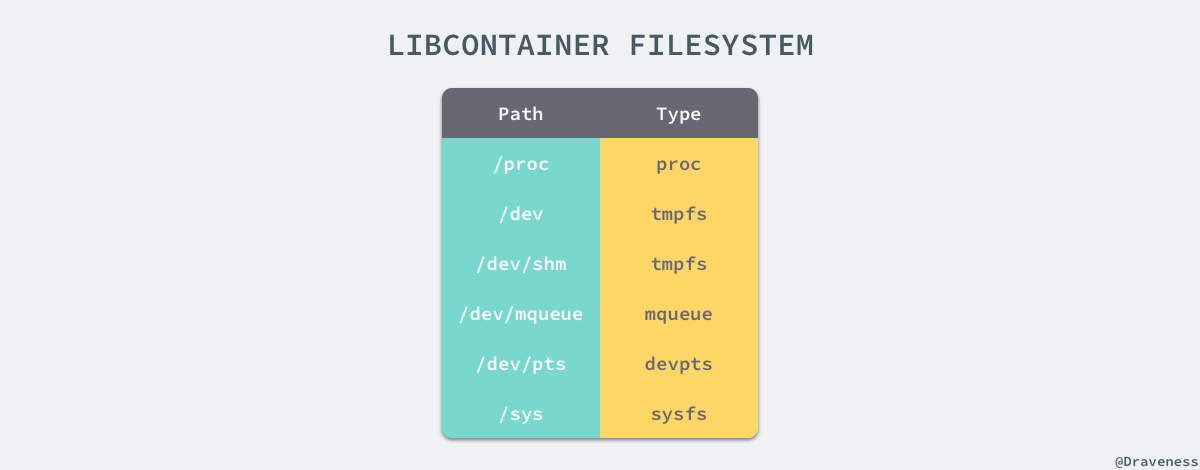
想要正常启动一个容器就需要在 rootfs 中挂载以上的几个特定的目录,除了上述的几个目录需要挂载之外我们还需要建立一些符号链接保证系统 IO 不会出现问题。
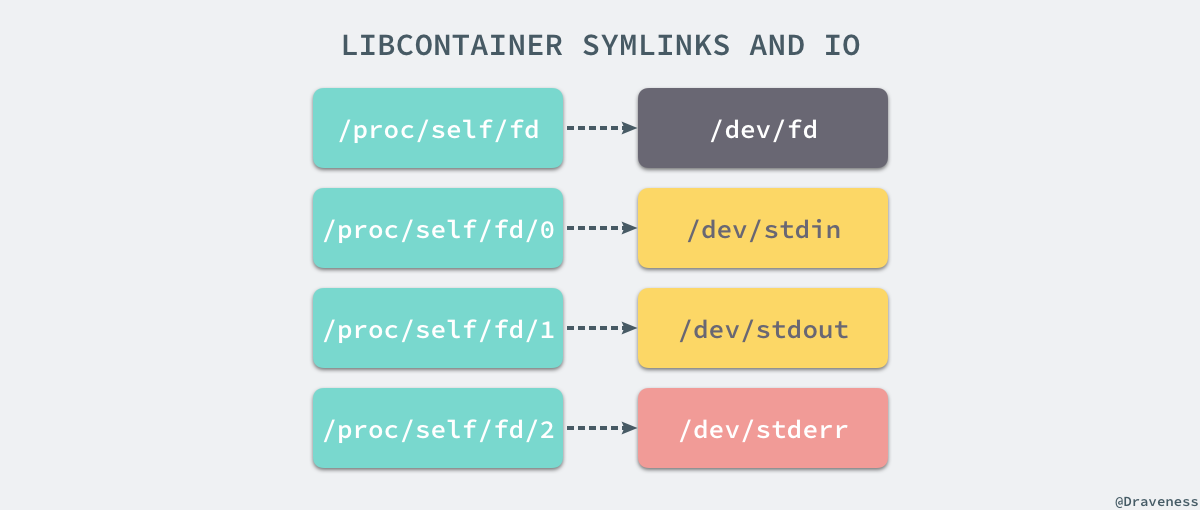
为了保证当前的容器进程没有办法访问宿主机器上其他目录,我们在这里还需要通过 libcontainer 提供的 pivot_root 或者 chroot 函数改变进程能够访问个文件目录的根节点。
1 | // pivor_rootput_old = mkdir(...);pivot_root(rootfs, put_old);chdir("/");unmount(put_old, MS_DETACH);rmdir(put_old); // chrootmount(rootfs, "/", NULL, MS_MOVE, NULL);chroot(".");chdir("/"); |
到这里我们就将容器需要的目录挂载到了容器中,同时也禁止当前的容器进程访问宿主机器上的其他目录,保证了不同文件系统的隔离。
这一部分的内容是作者在 libcontainer 中的 SPEC.md 文件中找到的,其中包含了 Docker 使用的文件系统的说明,对于 Docker 是否真的使用
chroot来确保当前的进程无法访问宿主机器的目录,作者其实也没有确切的答案,一是 Docker 项目的代码太多庞大,不知道该从何入手,作者尝试通过 Google 查找相关的结果,但是既找到了无人回答的 问题,也得到了与 SPEC 中的描述有冲突的 答案 ,如果各位读者有明确的答案可以在博客下面留言,非常感谢。
在这里不得不简单介绍一下 chroot(change root),在 Linux 系统中,系统默认的目录就都是以 / 也就是根目录开头的,chroot 的使用能够改变当前的系统根目录结构,通过改变当前系统的根目录,我们能够限制用户的权利,在新的根目录下并不能够访问旧系统根目录的结构个文件,也就建立了一个与原系统完全隔离的目录结构。
与 chroot 的相关内容部分来自 理解 chroot 一文,各位读者可以阅读这篇文章获得更详细的信息。
我们通过 Linux 的命名空间为新创建的进程隔离了文件系统、网络并与宿主机器之间的进程相互隔离,但是命名空间并不能够为我们提供物理资源上的隔离,比如 CPU 或者内存,如果在同一台机器上运行了多个对彼此以及宿主机器一无所知的『容器』,这些容器却共同占用了宿主机器的物理资源。
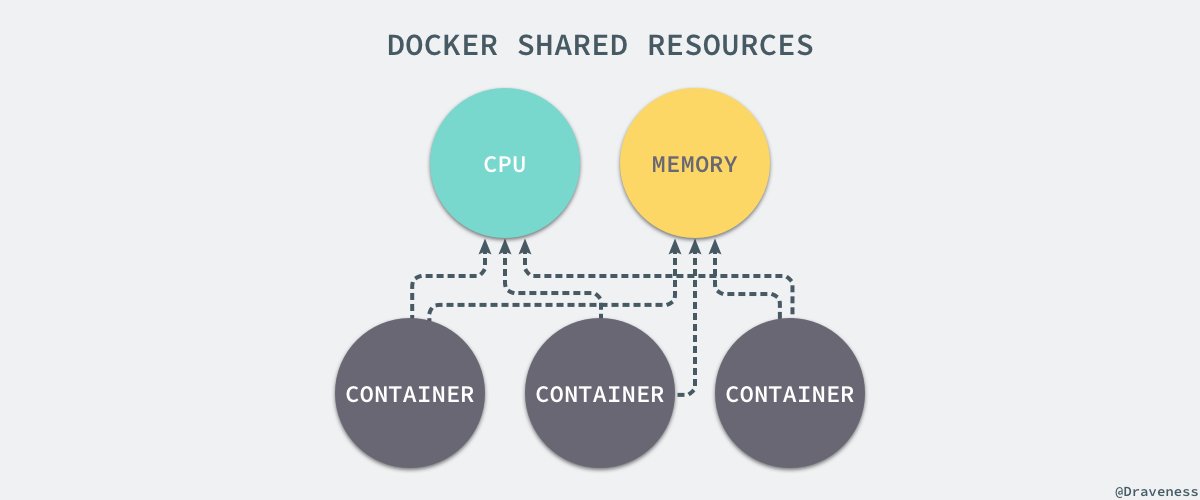
如果其中的某一个容器正在执行 CPU 密集型的任务,那么就会影响其他容器中任务的性能与执行效率,导致多个容器相互影响并且抢占资源。如何对多个容器的资源使用进行限制就成了解决进程虚拟资源隔离之后的主要问题,而 Control Groups(简称 CGroups)就是能够隔离宿主机器上的物理资源,例如 CPU、内存、磁盘 I/O 和网络带宽。
每一个 CGroup 都是一组被相同的标准和参数限制的进程,不同的 CGroup 之间是有层级关系的,也就是说它们之间可以从父类继承一些用于限制资源使用的标准和参数。
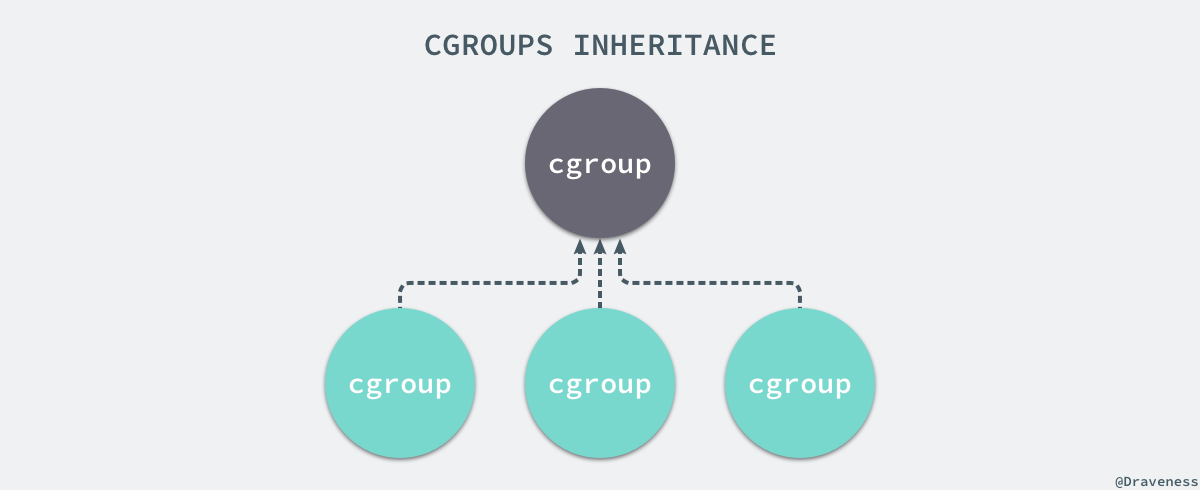
Linux 的 CGroup 能够为一组进程分配资源,也就是我们在上面提到的 CPU、内存、网络带宽等资源,通过对资源的分配,CGroup 能够提供以下的几种功能:
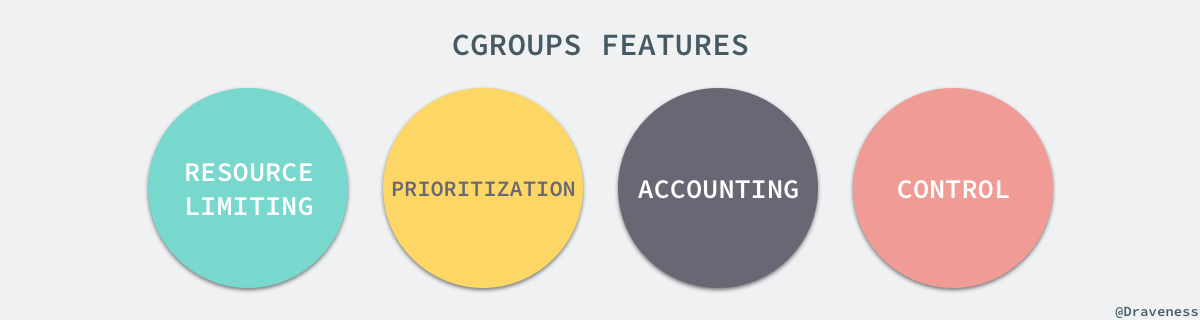
在 CGroup 中,所有的任务就是一个系统的一个进程,而 CGroup 就是一组按照某种标准划分的进程,在 CGroup 这种机制中,所有的资源控制都是以 CGroup 作为单位实现的,每一个进程都可以随时加入一个 CGroup 也可以随时退出一个 CGroup。
Linux 使用文件系统来实现 CGroup,我们可以直接使用下面的命令查看当前的 CGroup 中有哪些子系统:
1 | $ lssubsys -mcpuset /sys/fs/cgroup/cpusetcpu /sys/fs/cgroup/cpucpuacct /sys/fs/cgroup/cpuacctmemory /sys/fs/cgroup/memorydevices /sys/fs/cgroup/devicesfreezer /sys/fs/cgroup/freezerblkio /sys/fs/cgroup/blkioperf_event /sys/fs/cgroup/perf_eventhugetlb /sys/fs/cgroup/hugetlb |
大多数 Linux 的发行版都有着非常相似的子系统,而之所以将上面的 cpuset、cpu 等东西称作子系统,是因为它们能够为对应的控制组分配资源并限制资源的使用。
如果我们想要创建一个新的 cgroup 只需要在想要分配或者限制资源的子系统下面创建一个新的文件夹,然后这个文件夹下就会自动出现很多的内容,如果你在 Linux 上安装了 Docker,你就会发现所有子系统的目录下都有一个名为 docker 的文件夹:
1 | $ ls cpucgroup.clone_children ...cpu.stat docker notify_on_release release_agent tasks $ ls cpu/docker/9c3057f1291b53fd54a3d12023d2644efe6a7db6ddf330436ae73ac92d401cf1 cgroup.clone_children ...cpu.stat notify_on_release release_agent tasks |
9c3057xxx 其实就是我们运行的一个 Docker 容器,启动这个容器时,Docker 会为这个容器创建一个与容器标识符相同的 CGroup,在当前的主机上 CGroup 就会有以下的层级关系:
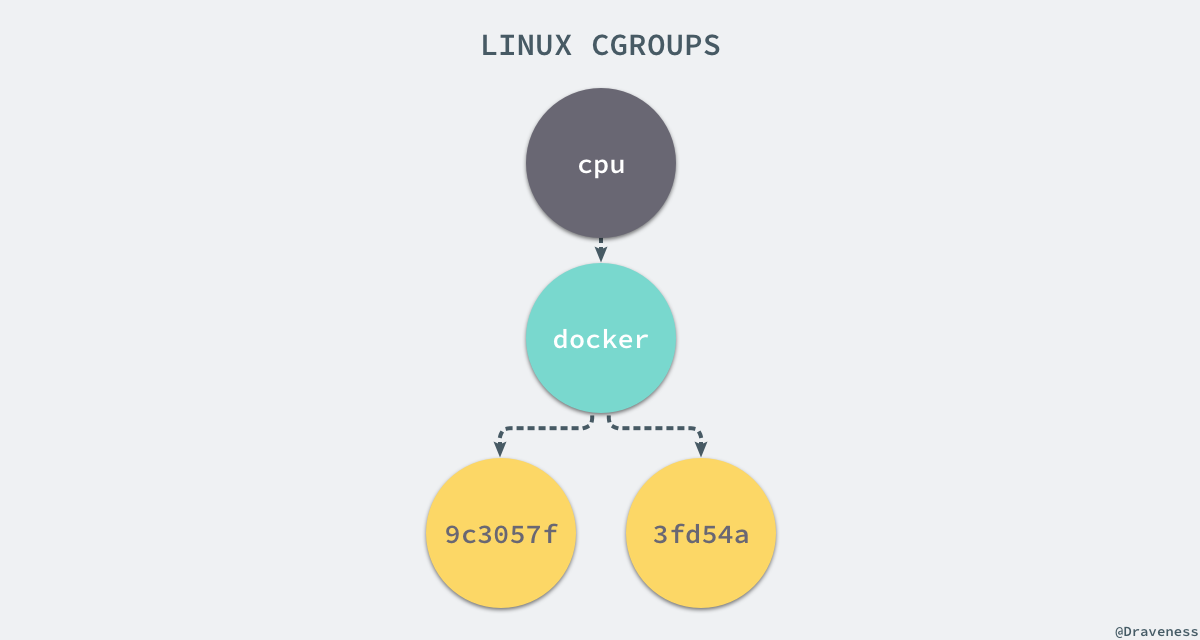
每一个 CGroup 下面都有一个 tasks 文件,其中存储着属于当前控制组的所有进程的 pid,作为负责 cpu 的子系统,cpu.cfs_quota_us 文件中的内容能够对 CPU 的使用作出限制,如果当前文件的内容为 50000,那么当前控制组中的全部进程的 CPU 占用率不能超过 50%。
如果系统管理员想要控制 Docker 某个容器的资源使用率就可以在 docker这个父控制组下面找到对应的子控制组并且改变它们对应文件的内容,当然我们也可以直接在程序运行时就使用参数,让 Docker 进程去改变相应文件中的内容。
1 | $ docker run -it -d --cpu-quota=50000 busybox53861305258ecdd7f5d2a3240af694aec9adb91cd4c7e210b757f71153cdd274$ cd 53861305258ecdd7f5d2a3240af694aec9adb91cd4c7e210b757f71153cdd274/$ lscgroup.clone_children cgroup.event_control cgroup.procs cpu.cfs_period_us cpu.cfs_quota_us cpu.shares cpu.stat notify_on_release tasks$ cat cpu.cfs_quota_us50000 |
当我们使用 Docker 关闭掉正在运行的容器时,Docker 的子控制组对应的文件夹也会被 Docker 进程移除,Docker 在使用 CGroup 时其实也只是做了一些创建文件夹改变文件内容的文件操作,不过 CGroup 的使用也确实解决了我们限制子容器资源占用的问题,系统管理员能够为多个容器合理的分配资源并且不会出现多个容器互相抢占资源的问题。
Linux 的命名空间和控制组分别解决了不同资源隔离的问题,前者解决了进程、网络以及文件系统的隔离,后者实现了 CPU、内存等资源的隔离,但是在 Docker 中还有另一个非常重要的问题需要解决 - 也就是镜像。
镜像到底是什么,它又是如何组成和组织的是作者使用 Docker 以来的一段时间内一直比较让作者感到困惑的问题,我们可以使用 docker run 非常轻松地从远程下载 Docker 的镜像并在本地运行。
Docker 镜像其实本质就是一个压缩包,我们可以使用下面的命令将一个 Docker 镜像中的文件导出:
1 | $ docker export $(docker create busybox) | tar -C rootfs -xvf -$ lsbin dev etc home proc root sys tmp usr var |
你可以看到这个 busybox 镜像中的目录结构与 Linux 操作系统的根目录中的内容并没有太多的区别,可以说 Docker 镜像就是一个文件。
Docker 使用了一系列不同的存储驱动管理镜像内的文件系统并运行容器,这些存储驱动与 Docker 卷(volume)有些不同,存储引擎管理着能够在多个容器之间共享的存储。
想要理解 Docker 使用的存储驱动,我们首先需要理解 Docker 是如何构建并且存储镜像的,也需要明白 Docker 的镜像是如何被每一个容器所使用的;Docker 中的每一个镜像都是由一系列只读的层组成的,Dockerfile 中的每一个命令都会在已有的只读层上创建一个新的层:
1 | FROM ubuntu:15.04COPY . /appRUN make /appCMD python /app/app.py |
容器中的每一层都只对当前容器进行了非常小的修改,上述的 Dockerfile 文件会构建一个拥有四层 layer 的镜像:
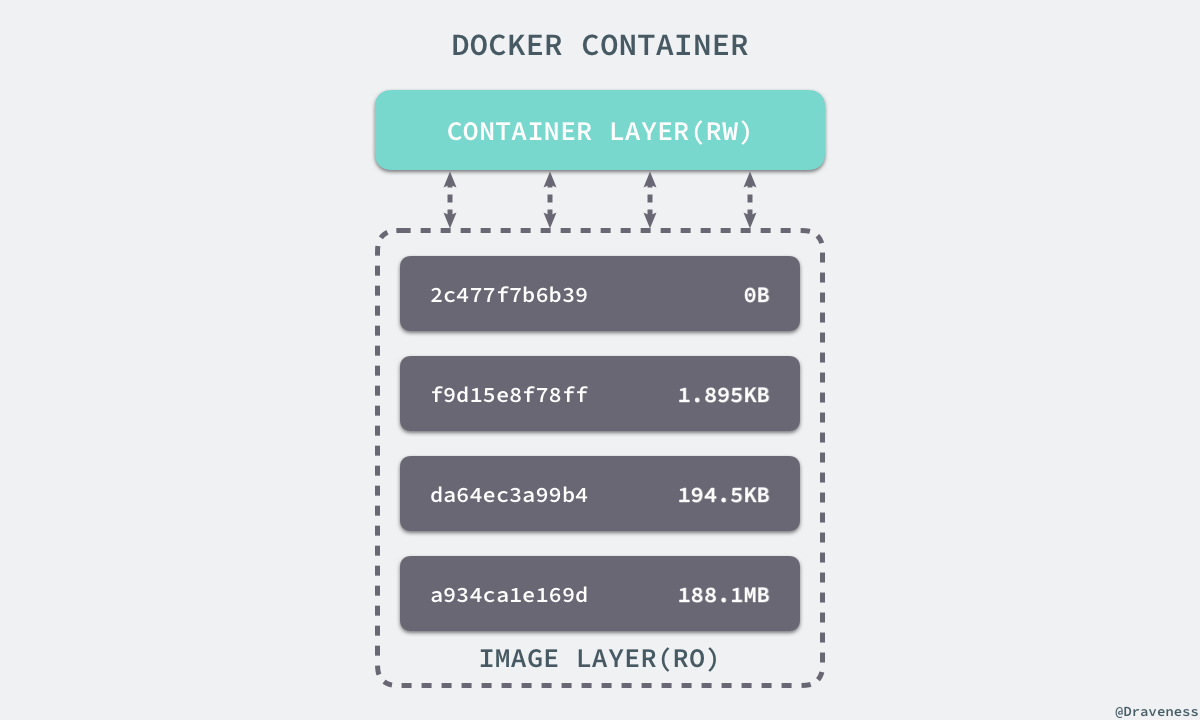
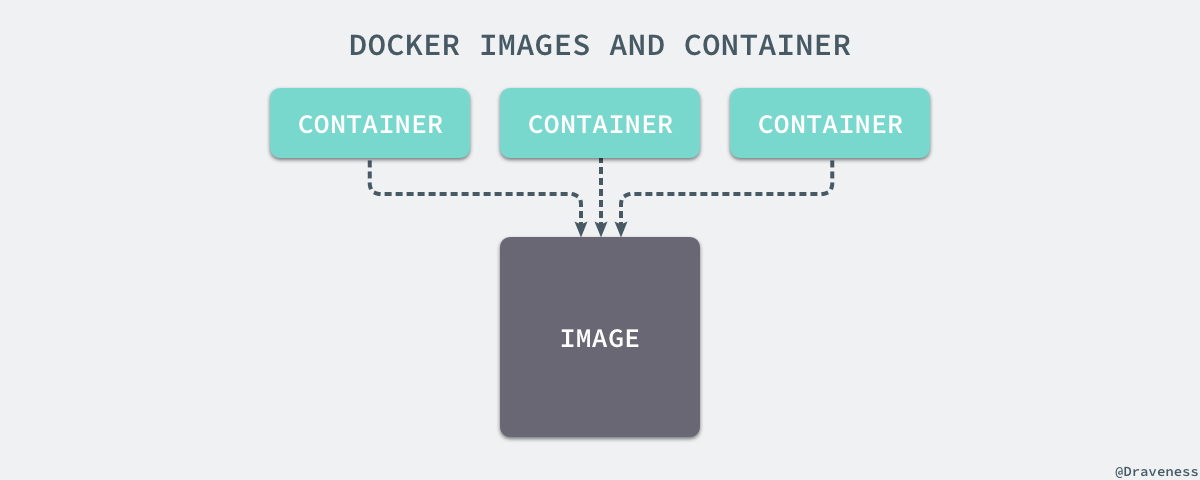
当镜像被 docker run 命令创建时就会在镜像的最上层添加一个可写的层,也就是容器层,所有对于运行时容器的修改其实都是对这个容器读写层的修改。
容器和镜像的区别就在于,所有的镜像都是只读的,而每一个容器其实等于镜像加上一个可读写的层,也就是同一个镜像可以对应多个容器。
UnionFS 其实是一种为 Linux 操作系统设计的用于把多个文件系统『联合』到同一个挂载点的文件系统服务。而 AUFS 即 Advanced UnionFS 其实就是 UnionFS 的升级版,它能够提供更优秀的性能和效率。
AUFS 作为联合文件系统,它能够将不同文件夹中的层联合(Union)到了同一个文件夹中,这些文件夹在 AUFS 中称作分支,整个『联合』的过程被称为_联合挂载(Union Mount)_:
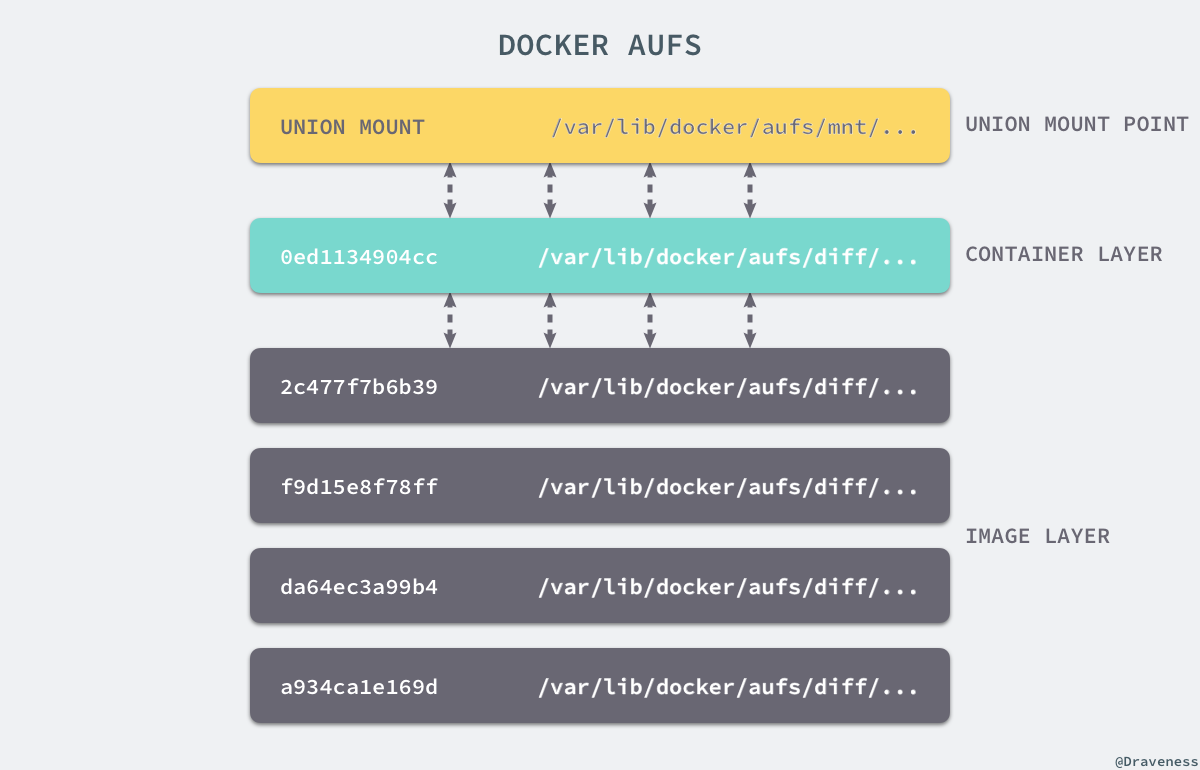
每一个镜像层或者容器层都是 /var/lib/docker/ 目录下的一个子文件夹;在 Docker 中,所有镜像层和容器层的内容都存储在 /var/lib/docker/aufs/diff/ 目录中:
1 | $ ls /var/lib/docker/aufs/diff/00adcccc1a55a36a610a6ebb3e07cc35577f2f5a3b671be3dbc0e74db9ca691c 93604f232a831b22aeb372d5b11af8c8779feb96590a6dc36a80140e38e764d800adcccc1a55a36a610a6ebb3e07cc35577f2f5a3b671be3dbc0e74db9ca691c-init 93604f232a831b22aeb372d5b11af8c8779feb96590a6dc36a80140e38e764d8-init019a8283e2ff6fca8d0a07884c78b41662979f848190f0658813bb6a9a464a90 93b06191602b7934fafc984fbacae02911b579769d0debd89cf2a032e7f35cfa... |
而 /var/lib/docker/aufs/layers/ 中存储着镜像层的元数据,每一个文件都保存着镜像层的元数据,最后的 /var/lib/docker/aufs/mnt/ 包含镜像或者容器层的挂载点,最终会被 Docker 通过联合的方式进行组装。

上面的这张图片非常好的展示了组装的过程,每一个镜像层都是建立在另一个镜像层之上的,同时所有的镜像层都是只读的,只有每个容器最顶层的容器层才可以被用户直接读写,所有的容器都建立在一些底层服务(Kernel)上,包括命名空间、控制组、rootfs 等等,这种容器的组装方式提供了非常大的灵活性,只读的镜像层通过共享也能够减少磁盘的占用。
AUFS 只是 Docker 使用的存储驱动的一种,除了 AUFS 之外,Docker 还支持了不同的存储驱动,包括 aufs、devicemapper、overlay2、zfs 和 vfs 等等,在最新的 Docker 中,overlay2 取代了 aufs 成为了推荐的存储驱动,但是在没有 overlay2 驱动的机器上仍然会使用 aufs 作为 Docker 的默认驱动。
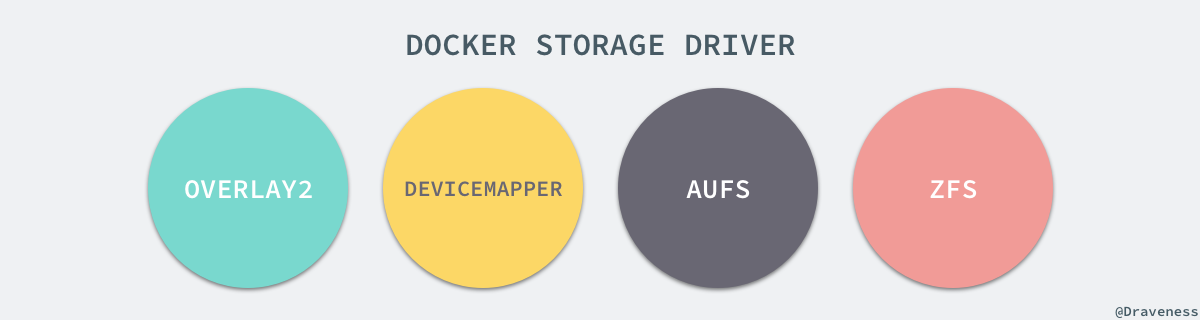
不同的存储驱动在存储镜像和容器文件时也有着完全不同的实现,有兴趣的读者可以在 Docker 的官方文档 Select a storage driver 中找到相应的内容。
想要查看当前系统的 Docker 上使用了哪种存储驱动只需要使用以下的命令就能得到相对应的信息:
1 | $ docker info | grep StorageStorage Driver: aufs |
作者的这台 Ubuntu 上由于没有 overlay2 存储驱动,所以使用 aufs 作为 Docker 的默认存储驱动。
Docker 目前已经成为了非常主流的技术,已经在很多成熟公司的生产环境中使用,但是 Docker 的核心技术其实已经有很多年的历史了,Linux 命名空间、控制组和 UnionFS 三大技术支撑了目前 Docker 的实现,也是 Docker 能够出现的最重要原因。
作者在学习 Docker 实现原理的过程中查阅了非常多的资料,从中也学习到了很多与 Linux 操作系统相关的知识,不过由于 Docker 目前的代码库实在是太过庞大,想要从源代码的角度完全理解 Docker 实现的细节已经是非常困难的了,但是如果各位读者真的对其实现细节感兴趣,可以从 Docker CE 的源代码开始了解 Docker 的原理。
微信公众号【程序员黄小斜】新生代青年聚集地,程序员成长充电站。作者黄小斜,职业是阿里程序员,身份是斜杠青年,希望和更多的程序员交朋友,一起进步和成长!这一次,我们一起出发。
关注公众号后回复“2019”领取我这两年整理的学习资料,涵盖自学编程、求职面试、算法刷题、Java技术、计算机基础和考研等8000G资料合集。
微信公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,专注于 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
关注公众号后回复“PDF”即可领取200+页的《Java工程师面试指南》强烈推荐,几乎涵盖所有Java工程师必知必会的知识点。
本文只是对Docker的概念做了较为详细的介绍,并不涉及一些像Docker环境的安装以及Docker的一些常见操作和命令。
阅读本文大概需要15分钟,通过阅读本文你将知道一下概念:
Docker 是世界领先的软件容器平台,所以想要搞懂Docker的概念我们必须先从容器开始说起。
一句话概括容器:容器就是将软件打包成标准化单元,以用于开发、交付和部署。
如果需要通俗的描述容器的话,我觉得容器就是一个存放东西的地方,就像书包可以装各种文具、衣柜可以放各种衣服、鞋架可以放各种鞋子一样。我们现在所说的容器存放的东西可能更偏向于应用比如网站、程序甚至是系统环境。
关于虚拟机与容器的对比在后面会详细介绍到,这里只是通过网上的图片加深大家对于物理机、虚拟机与容器这三者的理解。
物理机
虚拟机:
容器:
通过上面这三张抽象图,我们可以大概可以通过类比概括出: 容器虚拟化的是操作系统而不是硬件,容器之间是共享同一套操作系统资源的。虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统。因此容器的隔离级别会稍低一些。
相信通过上面的解释大家对于容器这个既陌生又熟悉的概念有了一个初步的认识,下面我们就来谈谈Docker的一些概念。
说实话关于Docker是什么并太好说,下面我通过四点向你说明Docker到底是个什么东西。
在一台机器上运行的多个 Docker 容器可以共享这台机器的操作系统内核;它们能够迅速启动,只需占用很少的计算和内存资源。镜像是通过文件系统层进行构造的,并共享一些公共文件。这样就能尽量降低磁盘用量,并能更快地下载镜像。
Docker 容器基于开放式标准,能够在所有主流 Linux 版本、Microsoft Windows 以及包括 VM、裸机服务器和云在内的任何基础设施上运行。
Docker 赋予应用的隔离性不仅限于彼此隔离,还独立于底层的基础设施。Docker 默认提供最强的隔离,因此应用出现问题,也只是单个容器的问题,而不会波及到整台机器。
每当说起容器,我们不得不将其与虚拟机做一个比较。就我而言,对于两者无所谓谁会取代谁,而是两者可以和谐共存。
简单来说: 容器和虚拟机具有相似的资源隔离和分配优势,但功能有所不同,因为容器虚拟化的是操作系统,而不是硬件,因此容器更容易移植,效率也更高。
传统虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统,在该系统上再运行所需应用进程;而容器内的应用进程直接运行于宿主的内核,容器内没有自己的内核,而且也没有进行硬件虚拟。因此容器要比传统虚拟机更为轻便.
容器是一个应用层抽象,用于将代码和依赖资源打包在一起。 多个容器可以在同一台机器上运行,共享操作系统内核,但各自作为独立的进程在用户空间中运行 。与虚拟机相比, 容器占用的空间较少(容器镜像大小通常只有几十兆),瞬间就能完成启动 。
虚拟机 (VM) 是一个物理硬件层抽象,用于将一台服务器变成多台服务器。 管理程序允许多个 VM 在一台机器上运行。每个VM都包含一整套操作系统、一个或多个应用、必要的二进制文件和库资源,因此 占用大量空间 。而且 VM 启动也十分缓慢 。
通过Docker官网,我们知道了这么多Docker的优势,但是大家也没有必要完全否定虚拟机技术,因为两者有不同的使用场景。虚拟机更擅长于彻底隔离整个运行环境。例如,云服务提供商通常采用虚拟机技术隔离不同的用户。而 Docker通常用于隔离不同的应用 ,例如前端,后端以及数据库。
就我而言,对于两者无所谓谁会取代谁,而是两者可以和谐共存。
Docker中非常重要的三个基本概念,理解了这三个概念,就理解了 Docker 的整个生命周期。
Docker 包括三个基本概念
理解了这三个概念,就理解了 Docker 的整个生命周期
操作系统分为内核和用户空间。对于 Linux 而言,内核启动后,会挂载 root 文件系统为其提供用户空间支持。而Docker 镜像(Image),就相当于是一个 root 文件系统。
Docker 镜像是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)。 镜像不包含任何动态数据,其内容在构建之后也不会被改变。
Docker 设计时,就充分利用 Union FS的技术,将其设计为 分层存储的架构 。 镜像实际是由多层文件系统联合组成。
镜像构建时,会一层层构建,前一层是后一层的基础。每一层构建完就不会再发生改变,后一层上的任何改变只发生在自己这一层。 比如,删除前一层文件的操作,实际不是真的删除前一层的文件,而是仅在当前层标记为该文件已删除。在最终容器运行的时候,虽然不会看到这个文件,但是实际上该文件会一直跟随镜像。因此,在构建镜像的时候,需要额外小心,每一层尽量只包含该层需要添加的东西,任何额外的东西应该在该层构建结束前清理掉。
分层存储的特征还使得镜像的复用、定制变的更为容易。甚至可以用之前构建好的镜像作为基础层,然后进一步添加新的层,以定制自己所需的内容,构建新的镜像。
镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的 类 和 实例 一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。
容器的实质是进程,但与直接在宿主执行的进程不同,容器进程运行于属于自己的独立的 命名空间。前面讲过镜像使用的是分层存储,容器也是如此。
容器存储层的生存周期和容器一样,容器消亡时,容器存储层也随之消亡。因此,任何保存于容器存储层的信息都会随容器删除而丢失。
按照 Docker 最佳实践的要求,容器不应该向其存储层内写入任何数据 ,容器存储层要保持无状态化。所有的文件写入操作,都应该使用数据卷(Volume)、或者绑定宿主目录,在这些位置的读写会跳过容器存储层,直接对宿主(或网络存储)发生读写,其性能和稳定性更高。数据卷的生存周期独立于容器,容器消亡,数据卷不会消亡。因此, 使用数据卷后,容器可以随意删除、重新 run ,数据却不会丢失。
镜像构建完成后,可以很容易的在当前宿主上运行,但是, 如果需要在其它服务器上使用这个镜像,我们就需要一个集中的存储、分发镜像的服务,Docker Registry就是这样的服务。
一个 Docker Registry中可以包含多个仓库(Repository);每个仓库可以包含多个标签(Tag);每个标签对应一个镜像。所以说:镜像仓库是Docker用来集中存放镜像文件的地方类似于我们之前常用的代码仓库。
通常,一个仓库会包含同一个软件不同版本的镜像,而标签就常用于对应该软件的各个版本 。我们可以通过<仓库名>:<标签>的格式来指定具体是这个软件哪个版本的镜像。如果不给出标签,将以 latest 作为默认标签.。
这里补充一下Docker Registry 公开服务和私有 Docker Registry的概念:
Docker Registry 公开服务 是开放给用户使用、允许用户管理镜像的 Registry 服务。一般这类公开服务允许用户免费上传、下载公开的镜像,并可能提供收费服务供用户管理私有镜像。
最常使用的 Registry 公开服务是官方的 Docker Hub ,这也是默认的 Registry,并拥有大量的高质量的官方镜像,网址为:hub.docker.com/ 。在国内访问Docker Hub 可能会比较慢国内也有一些云服务商提供类似于 Docker Hub 的公开服务。比如 时速云镜像库、网易云镜像服务、DaoCloud 镜像市场、阿里云镜像库等。
除了使用公开服务外,用户还可以在 本地搭建私有 Docker Registry 。Docker 官方提供了 Docker Registry 镜像,可以直接使用做为私有 Registry 服务。开源的 Docker Registry 镜像只提供了 Docker Registry API 的服务端实现,足以支持 docker 命令,不影响使用。但不包含图形界面,以及镜像维护、用户管理、访问控制等高级功能。
Docker的概念基本上已经讲完,最后我们谈谈:Build, Ship, and Run。
如果你搜索Docker官网,会发现如下的字样:“Docker - Build, Ship, and Run Any App, Anywhere”。那么Build, Ship, and Run到底是在干什么呢?
Docker 运行过程也就是去仓库把镜像拉到本地,然后用一条命令把镜像运行起来变成容器。所以,我们也常常将Docker称为码头工人或码头装卸工,这和Docker的中文翻译搬运工人如出一辙。
本文主要把Docker中的一些常见概念做了详细的阐述,但是并不涉及Docker的安装、镜像的使用、容器的操作等内容。这部分东西,希望读者自己可以通过阅读书籍与官方文档的形式掌握。如果觉得官方文档阅读起来很费力的话,这里推荐一本书籍《Docker技术入门与实战第二版》。
微信公众号【程序员黄小斜】新生代青年聚集地,程序员成长充电站。作者黄小斜,职业是阿里程序员,身份是斜杠青年,希望和更多的程序员交朋友,一起进步和成长!这一次,我们一起出发。
关注公众号后回复“2019”领取我这两年整理的学习资料,涵盖自学编程、求职面试、算法刷题、Java技术、计算机基础和考研等8000G资料合集。
微信公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,专注于 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
关注公众号后回复“PDF”即可领取200+页的《Java工程师面试指南》强烈推荐,几乎涵盖所有Java工程师必知必会的知识点。
OpenStack 是开源云计算平台,支持多种虚拟化环境,并且其服务组件都提供了 API接口 便于二次开发。
OpenStack通过各种补充服务提供基础设施即服务 Infrastructure-as-a-Service (IaaS)的解决方案。每个服务都提供便于集成的应用程序接口Application Programming Interface (API)。
OpenStack 本身是一个分布式系统,不但各个服务可以分布部署,服务中的组件也可以分布部署。 这种分布式特性让 OpenStack 具备极大的灵活性、伸缩性和高可用性。 当然从另一个角度讲,这也使得 OpenStack 比一般系统复杂,学习难度也更大。
后面章节我们会深入学习 Keystone、Glance、Nova、Neutron 和 Cinder 这几个 OpenStack 最重要最核心的服务。
openstack的核心和扩展的主要项目如下:
OpenStack Compute (code-name Nova) 计算服务
OpenStack Networking (code-name Neutron) 网络服务
OpenStack Object Storage (code-name Swift) 对象存储服务
OpenStack Block Storage (code-name Cinder) 块设备存储服务
OpenStack Identity (code-name Keystone) 认证服务
OpenStack Image Service (code-name Glance) 镜像文件服务
OpenStack Dashboard (code-name Horizon) 仪表盘服务
OpenStack Telemetry (code-name Ceilometer) 告警服务
OpenStack Orchestration (code-name Heat) 流程服务
OpenStack Database (code-name Trove) 数据库服务
OpenStack的各个服务之间通过统一的REST风格的API调用,实现系统的松耦合。上图是OpenStack各个服务之间API调用的概览,其中实线代表client 的API调用,虚线代表各个组件之间通过rpc调用进行通信。松耦合架构的好处是,各个组件的开发人员可以只关注各自的领域,对各自领域的修改不会影响到其他开发人员。不过从另一方面来讲,这种松耦合的架构也给整个系统的维护带来了一定的困难,运维人员要掌握更多的系统相关的知识去调试出了问题的组件。所以无论对于开发还是维护人员,搞清楚各个组件之间的相互调用关系是怎样的都是非常必要的。
对Linux经验丰富的OpenStack新用户,使用openstack是非常容易的,在后续openstack系列文章中会逐步展开介绍。
OpenStack services
Dashboard 【Horizon】 提供了一个基于web的自服务门户,与OpenStack底层服务交互,诸如启动一个实例,分配IP地址以及配置访问控制。
Compute 【Nova】 在OpenStack环境中计算实例的生命周期管理。按需响应包括生成、调度、回收虚拟机等操作。
Networking 【Neutron】 确保为其它OpenStack服务提供网络连接即服务,比如OpenStack计算。为用户提供API定义网络和使用。基于插件的架构其支持众多的网络提供商和技术。
Object Storage 【Swift】 通过一个 RESTful,基于HTTP的应用程序接口存储和任意检索的非结构化数据对象。它拥有高容错机制,基于数据复制和可扩展架构。它的实现并像是一个文件服务器需要挂载目录。在此种方式下,它写入对象和文件到多个硬盘中,以确保数据是在集群内跨服务器的多份复制。
Block Storage 【Cinder】 为运行实例而提供的持久性块存储。它的可插拔驱动架构的功能有助于创建和管理块存储设备。
Identity service 【Keystone】 为其他OpenStack服务提供认证和授权服务,为所有的OpenStack服务提供一个端点目录。
Image service 【Glance】 存储和检索虚拟机磁盘镜像,OpenStack计算会在实例部署时使用此服务。
Telemetry服务 【Ceilometer】 为OpenStack云的计费、基准、扩展性以及统计等目的提供监测和计量。
Orchestration服务 【Heat服务】 Orchestration服务支持多样化的综合的云应用,通过调用OpenStack-native REST API和CloudFormation-compatible Query API,支持HOT <Heat Orchestration Template (HOT)>格式模板或者AWS CloudFormation格式模板
通过对这些组件的介绍,可以帮助我们在后续的内容中,了解各个组件的作用,便于排查问题,而在你对基础安装,配置,操作和故障诊断熟悉之后,你应该考虑按照生产架构来进行部署。
建议使用自动化部署工具,例如Ansible, Chef, Puppet, or Salt来自动化部署,管理生产环境。
这个示例架构需要至少2个(主机)节点来启动基础服务virtual machine <virtual machine (VM)>或者实例。像块存储服务,对象存储服务这一类服务还需要额外的节点。
网络代理驻留在控制节点上而不是在一个或者多个专用的网络节点上。
私有网络的覆盖流量通过管理网络而不是专用网络
控制节点上运行身份认证服务,镜像服务,计算服务的管理部分,网络服务的管理部分,多种网络代理以及仪表板。也需要包含一些支持服务,例如:SQL数据库,term:消息队列, and NTP。
可选的,可以在计算节点上运行部分块存储,对象存储,Orchestration 和 Telemetry 服务。
计算节点上需要至少两块网卡。
计算节点上运行计算服务中管理实例的管理程序部分。默认情况下,计算服务使用 KVM。
你可以部署超过一个计算节点。每个结算节点至少需要两块网卡。
可选的块存储节点上包含了磁盘,块存储服务和共享文件系统会向实例提供这些磁盘。
为了简单起见,计算节点和本节点之间的服务流量使用管理网络。生产环境中应该部署一个单独的存储网络以增强性能和安全。
你可以部署超过一个块存储节点。每个块存储节点要求至少一块网卡。
可选的对象存储节点包含了磁盘。对象存储服务用这些磁盘来存储账号,容器和对象。
为了简单起见,计算节点和本节点之间的服务流量使用管理网络。生产环境中应该部署一个单独的存储网络以增强性能和安全。
这个服务要求两个节点。每个节点要求最少一块网卡。你可以部署超过两个对象存储节点。
openstack网络是非常复杂的,并且也支持多种模式其中支持GRE,VLAN,VXLAN等,在openstack中网络是通过一个组件Neutron提供服务,Neutron 管理的网络资源包括如下。
network 是一个隔离的二层广播域。Neutron 支持多种类型的 network,包括 local, flat, VLAN, VxLAN 和 GRE。
local 网络与其他网络和节点隔离。local 网络中的 instance 只能与位于同一节点上同一网络的 instance 通信,local 网络主要用于单机测试。
flat 网络是无 vlan tagging 的网络。flat 网络中的 instance 能与位于同一网络的 instance 通信,并且可以跨多个节点。
vlan 网络是具有 802.1q tagging 的网络。vlan 是一个二层的广播域,同一 vlan 中的 instance 可以通信,不同 vlan 只能通过 router 通信。vlan 网络可以跨节点,是应用最广泛的网络类型。
vxlan 是基于隧道技术的 overlay 网络。vxlan 网络通过唯一的 segmentation ID(也叫 VNI)与其他 vxlan 网络区分。vxlan 中数据包会通过 VNI 封装成 UPD 包进行传输。因为二层的包通过封装在三层传输,能够克服 vlan 和物理网络基础设施的限制。
gre 是与 vxlan 类似的一种 overlay 网络。主要区别在于使用 IP 包而非 UDP 进行封装。 不同 network 之间在二层上是隔离的。以 vlan 网络为例,network A 和 network B 会分配不同的 VLAN ID,这样就保证了 network A 中的广播包不会跑到 network B 中。当然,这里的隔离是指二层上的隔离,借助路由器不同 network 是可能在三层上通信的。network 必须属于某个 Project( Tenant 租户),Project 中可以创建多个 network。 network 与 Project 之间是 1对多关系。
subnet 是一个 IPv4 或者 IPv6 地址段。instance 的 IP 从 subnet 中分配。每个 subnet 需要定义 IP 地址的范围和掩码。
port 可以看做虚拟交换机上的一个端口。port 上定义了 MAC 地址和 IP 地址,当 instance 的虚拟网卡 VIF(Virtual Interface) 绑定到 port 时,port 会将 MAC 和 IP 分配给 VIF。port 与 subnet 是 1对多 关系。一个 port 必须属于某个 subnet;一个 subnet 可以有多个 port。
如上图所示,为VLAN模式下,网络节点的通信方式。
在我们后续实施安装的时候,选择使用VXLAN网络模式,下面我们来重点介绍一下VXLAN模式。
VXLAN网络模式,可以隔离广播风暴,不需要交换机配置chunk口,解决了vlan id个数限制,解决了gre点对点隧道个数过多问题,实现了大2层网络,可以让vm在机房之间无缝迁移,便于跨机房部署。缺点是,vxlan增加了ip头部大小,需要降低vm的mtu值,传输效率上会略有下降。
Neutron 的设计目标是实现“网络即服务”,为了达到这一目标,在设计上遵循了基于“软件定义网络”实现网络虚拟化的原则,在实现上充分利用了 Linux 系统上的各种网络相关的技术。理解了 Linux 系统上的这些概念将有利于快速理解 Neutron 的原理和实现。
bridge:网桥,Linux中用于表示一个能连接不同网络设备的虚拟设备,linux中传统实现的网桥类似一个hub设备,而ovs管理的网桥一般类似交换机。
br-int:bridge-integration,综合网桥,常用于表示实现主要内部网络功能的网桥。
br-ex:bridge-external,外部网桥,通常表示负责跟外部网络通信的网桥。
GRE:General Routing Encapsulation,一种通过封装来实现隧道的方式。在openstack中一般是基于L3的gre,即original pkt/GRE/IP/Ethernet
VETH:虚拟ethernet接口,通常以pair的方式出现,一端发出的网包,会被另一端接收,可以形成两个网桥之间的通道。
qvb:neutron veth, Linux Bridge-side
qvo:neutron veth, OVS-side
TAP设备:模拟一个二层的网络设备,可以接受和发送二层网包。
TUN设备:模拟一个三层的网络设备,可以接受和发送三层网包。
iptables:Linux 上常见的实现安全策略的防火墙软件。
Vlan:虚拟 Lan,同一个物理 Lan 下用标签实现隔离,可用标号为1-4094。
VXLAN:一套利用 UDP 协议作为底层传输协议的 Overlay 实现。一般认为作为 VLan 技术的延伸或替代者。
namespace:用来实现隔离的一套机制,不同 namespace 中的资源之间彼此不可见。
openstack是一个非法复杂的分布式软件,涉及到很多底层技术,我自己对一些网络的理解也是非常有限,主要还是应用层面的知识,所以本章内容写的比较浅显一些,有问题请留言?在下一章节我们会进入生产环境如何实施规划openstack集群,至于openstack底层的技术,我也没有很深入研究,如果有任何不恰当的地方可以进行留言,非常感谢!
微信公众号【程序员黄小斜】新生代青年聚集地,程序员成长充电站。作者黄小斜,职业是阿里程序员,身份是斜杠青年,希望和更多的程序员交朋友,一起进步和成长!这一次,我们一起出发。
关注公众号后回复“2019”领取我这两年整理的学习资料,涵盖自学编程、求职面试、算法刷题、Java技术、计算机基础和考研等8000G资料合集。
微信公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,专注于 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
关注公众号后回复“PDF”即可领取200+页的《Java工程师面试指南》强烈推荐,几乎涵盖所有Java工程师必知必会的知识点。
原创文章,转载请注明: 转载自Itweet的博客
当你安装了一台Linux,想启动一个KVM虚拟机的时候,你会发现需要安装不同的软件,启动虚拟机的时候,有多种方法:
virsh start
kvm命令
qemu命令
qemu-kvm命令
qemu-system-x86_64命令
这些之间是什么关系呢?请先阅读上一篇《白话虚拟化技术》
有了上一篇的基础,我们就能说清楚来龙去脉。
KVM(Kernel-based Virtual Machine的英文缩写)是内核内建的虚拟机。有点类似于 Xen ,但更追求更简便的运作,比如运行此虚拟机,仅需要加载相应的 kvm 模块即可后台待命。和 Xen 的完整模拟不同的是,KVM 需要芯片支持虚拟化技术(英特尔的 VT 扩展或者 AMD 的 AMD-V 扩展)。
首先看qemu,其中关键字emu,全称emulator,模拟器,所以单纯使用qemu是采用的完全虚拟化的模式。
Qemu向Guest OS模拟CPU,也模拟其他的硬件,GuestOS认为自己和硬件直接打交道,其实是同Qemu模拟出来的硬件打交道,Qemu将这些指令转译给真正的硬件。由于所有的指令都要从Qemu里面过一手,因而性能比较差

按照上一次的理论,完全虚拟化是非常慢的,所以要使用硬件辅助虚拟化技术Intel-VT,AMD-V,所以需要CPU硬件开启这个标志位,一般在BIOS里面设置。查看是否开启
对于Intel CPU 可用命令 grep “vmx” /proc/cpuinfo 判断
对于AMD CPU 可用命令 grep “svm” /proc/cpuinfo 判断
当确认开始了标志位之后,通过KVM,GuestOS的CPU指令不用经过Qemu转译,直接运行,大大提高了速度。
所以KVM在内核里面需要有一个模块,来设置当前CPU是Guest OS在用,还是Host OS在用。
查看内核模块中是否含有kvm, ubuntu默认加载这些模块

KVM内核模块通过/dev/kvm暴露接口,用户态程序可以通过ioctl来访问这个接口,例如书写下面的程序

Qemu将KVM整合进来,通过ioctl调用/dev/kvm接口,将有关CPU指令的部分交由内核模块来做,就是qemu-kvm (qemu-system-XXX)
Qemu-kvm对kvm的整合从release_0_5_1开始有branch,在1.3.0正式merge到master
qemu和kvm整合之后,CPU的性能问题解决了,另外Qemu还会模拟其他的硬件,如Network, Disk,同样全虚拟化的方式也会影响这些设备的性能。
于是qemu采取半虚拟化或者类虚拟化的方式,让Guest OS加载特殊的驱动来做这件事情。
例如网络需要加载virtio_net,存储需要加载virtio_blk,Guest需要安装这些半虚拟化驱动,GuestOS知道自己是虚拟机,所以数据直接发送给半虚拟化设备,经过特殊处理,例如排队,缓存,批量处理等性能优化方式,最终发送给真正的硬件,一定程度上提高了性能。
至此整个关系如下:
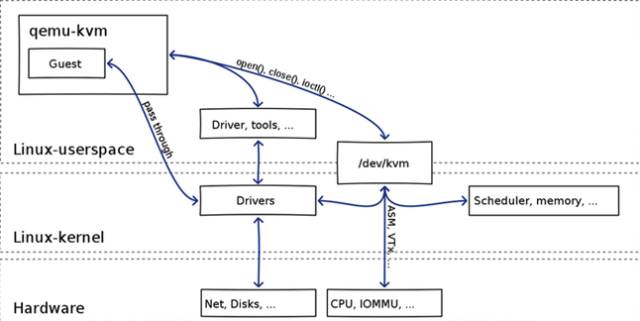
qemu-kvm会创建Guest OS,当需要执行CPU指令的时候,通过/dev/kvm调用kvm内核模块,通过硬件辅助虚拟化方式加速。如果需要进行网络和存储访问,则通过类虚拟化或者直通Pass through的方式,通过加载特殊的驱动,加速访问网络和存储资源。
然而直接用qemu或者qemu-kvm或者qemu-system-xxx的少,大多数还是通过virsh启动,virsh属于libvirt工具,libvirt是目前使用最为广泛的对KVM虚拟机进行管理的工具和API,可不止管理KVM。
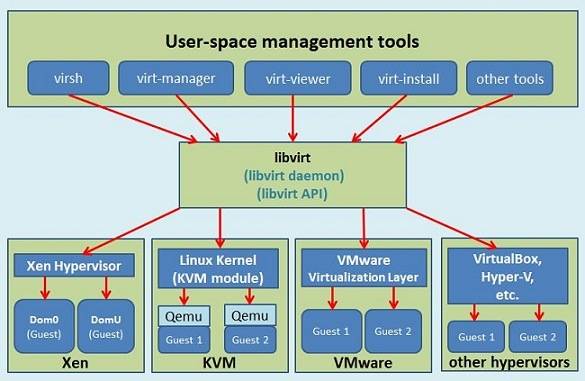
Libvirt分服务端和客户端,Libvirtd是一个daemon进程,是服务端,可以被本地的virsh调用,也可以被远程的virsh调用,virsh相当于客户端。
Libvirtd调用qemu-kvm操作虚拟机,有关CPU虚拟化的部分,qemu-kvm调用kvm的内核模块来实现
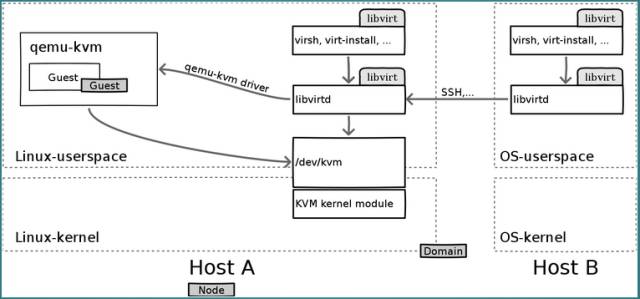
这下子,整个相互关系才搞清楚了。
虽然使用virsh创建虚拟机相对简单,但是为了探究虚拟机的究竟如何使用,下一次,我们来解析一下如何裸使用qemu-kvm来创建一台虚拟机,并且能上网。
如果搭建使用过vmware桌面版或者virtualbox桌面版,创建一个能上网的虚拟机非常简单,但是其实背后做了很多事情,下一次我们裸用qemu-kvm,全部使用手工配置,看创建虚拟机都做了哪些事情。
本章节我们主要介绍通过VMware技术虚拟出相关的Linux软件环境,在Linux系统中,安装KVM虚拟化软件,实实在在的去实践一下KVM到底是一个什么样的技术?
在VMware创建的虚拟机中,默认不支持Kvm虚拟化技术,需要芯片级的扩展支持,幸好VMware提供完整的解决方案,可以通过修改虚拟化引擎。
VMware软件版本信息,VMware® Workstation 11.0.0 build-2305329
首先,你需要启动VMware软件,新建一个CentOS 6.x类型的虚拟机,正常安装完成,这个虚拟机默认的虚拟化引擎,首选模式为”自动”。
如果想让我们的VMware虚拟化出来的CentOS虚拟机支持KVM虚拟化,我们需要修改它支持的虚拟化引擎,打开新建的虚拟机,虚拟机状态必须处于关闭状态,通过双击编辑虚拟机设置 > 硬件 ,选择处理器菜单,右边会出现虚拟化引擎区域,选择首选模式为 Intel Tv-x/EPT或AMD-V/RVI,接下来勾选虚拟化Intel Tv-x/EPT或AMD-V/RVI(v),点击确定。
KVM需要虚拟机宿主(host)的处理器带有虚拟化支持(对于Intel处理器来说是VT-x,对于AMD处理器来说是AMD-V)。你可以通过以下命令来检查你的处理器是否支持虚拟化:
1 | grep --color -E '(vmx|svm)' /proc/cpuinfo |
如果运行后没有显示,那么你的处理器不支持硬件虚拟化,你不能使用KVM。
安装kvm虚拟化软件,我们需要一个Linux操作系统环境,这里我们选择的Linux版本为CentOS release 6.8 (Final),在这个VMware虚拟化出来的虚拟机中安装kvm虚拟化软件,具体步骤如下:
首选安装epel源
1 | sudo rpm -ivh http://mirrors.ustc.edu.cn/fedora/epel/6/x86_64/epel-release-6-8.noarch.rpm |
安装kvm虚拟化软件
1 | sudo yum install qemu-kvm qeum-kvm-tools virt-manager libvirt |
启动kvm虚拟化软件
1 | sudo /etc/init.d/libvirtd start |
启动成功之后你可以通过/etc/init.d/libvirtd status查看启动状态,这个时候,kvm会自动生成一个本地网桥 virbr0,可以通过命令查看他的详细信息
1 | # ifconfig virbr0virbr0 Link encap:Ethernet HWaddr 52:54:00:D7:23:AD inet addr:192.168.122.1 Bcast:192.168.122.255 Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:0 errors:0 dropped:0 overruns:0 frame:0 TX packets:0 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:0 (0.0 b) TX bytes:0 (0.0 b) |
KVM默认使用NAT网络模式。虚拟机获取一个私有 IP(例如 192.168.122.0/24 网段的),并通过本地主机的NAT访问外网。
1 | # brctl showbridge name bridge id STP enabled interfacesvirbr0 8000.525400d723ad yes virbr0-nic |
创建一个本地网桥virbr0,包括两个端口:virbr0-nic 为网桥内部端口,vnet0 为虚拟机网关端口(192.168.122.1)。
虚拟机启动后,配置 192.168.122.1(vnet0)为网关。所有网络操作均由本地主机系统负责。
DNS/DHCP的实现,本地主机系统启动一个 dnsmasq 来负责管理。
1 | ps aux|grep dnsmasq |
注意: 启动libvirtd之后自动启动iptables,并且写上一些默认规则。
1 | # iptables -nvL -t natChain PREROUTING (policy ACCEPT 304 packets, 38526 bytes) pkts bytes target prot opt in out source destination Chain POSTROUTING (policy ACCEPT 7 packets, 483 bytes) pkts bytes target prot opt in out source destination 0 0 MASQUERADE tcp -- * * 192.168.122.0/24 !192.168.122.0/24 masq ports: 1024-65535 0 0 MASQUERADE udp -- * * 192.168.122.0/24 !192.168.122.0/24 masq ports: 1024-65535 0 0 MASQUERADE all -- * * 192.168.122.0/24 !192.168.122.0/24 Chain OUTPUT (policy ACCEPT 7 packets, 483 bytes) pkts bytes target prot opt in out source destination |
上传一个镜像文件:CentOS-6.6-x86_64-bin-DVD1.iso
通过qemu创建一个raw格式的文件(注:QEMU使用的镜像文件:qcow2与raw,它们都是QEMU(KVM)虚拟机使用的磁盘文件格式),大小为5G。
1 | qemu-img create -f raw /data/Centos-6.6-x68_64.raw 5G |
查看创建的raw磁盘格式文件信息
1 | qemu-img info /data/Centos-6.6-x68_64.raw image: /data/Centos-6.6-x68_64.rawfile format: rawvirtual size: 5.0G (5368709120 bytes)disk size: 0 |
启动,kvm虚拟机,进行操作系统安装
1 | virt-install --virt-type kvm --name CentOS-6.6-x86_64 --ram 512 --cdrom /data/CentOS-6.6-x86_64-bin-DVD1.iso --disk path=/data/Centos-6.6-x68_64.raw --network network=default --graphics vnc,listen=0.0.0.0 --noautoconsole |
启动之后,通过命令查看启动状态,默认会在操作系统开一个5900的端口,可以通过虚拟机远程管理软件vnc客户端连接,然后可视化的方式安装操作系统。
1 | # netstat -ntlp|grep 5900tcp 0 0 0.0.0.0:5900 0.0.0.0:* LISTEN 2504/qemu-kvm |
注意:kvm安装的虚拟机,不确定是那一台,在后台就是一个进程,每增加一台端口号+1,第一次创建的为5900!
我们可以使用虚拟机远程管理软件VNC进行操作系统的安装,我使用过的两款不错的虚拟机远程管理终端软件,一个是Windows上使用,一个在Mac上为了方便安装一个Google Chrome插件后即可开始使用,软件信息 Tightvnc 或者 VNC[@Viewer](https://link.juejin.im/?target=https%3A%2F%2Fgithub.com%2FViewer "@Viewer") for Google Chrome
如果你和我一样使用的是Google Chrome提供的VNC插件,使用方式,在Address输入框中输入,宿主机IP:59000,Picture Quality选择框使用默认选项,点击Connect进入到安装操作系统的界面,你可以安装常规的方式进行安装,等待系统安装完成重启,然后就可以正常使用kvm虚拟化出来的操作系统了。
Tightvnc软件的使用,请参考官方手册。
kvm虚拟机是通过virsh命令进行管理的,libvirt是Linux上的虚拟化库,是长期稳定的C语言API,支持KVM/QEMU、Xen、LXC等主流虚拟化方案。链接:libvirt.org/
virsh是Libvirt对应的shell命令。
查看所有虚拟机状态
1 | virsh list --all |
启动虚拟机
1 | virsh start [NAME] |
列表启动状态的虚拟机
1 | virsh list |
常用命令查看
1 | virsh --help|more less |
虚拟机libvirt配置文件在/etc/libvirt/qemu路径下,生产中我们需要去修改它的网络信息。
1 | # lltotal 8-rw-------. 1 root root 3047 Oct 19 2016 Centos-6.6-x68_64.xmldrwx------. 3 root root 4096 Oct 17 2016 networks |
注意:不能直接修改xml文件,需要通过提供的命令!
1 | virsh edit Centos-6.6-x68_64 |
kvm三种网络类型,桥接、NAT、仅主机模式,默认NAT模式,其他机器无法登陆,生产中一般选择桥接。
1 | yum install virt-top -y |
1 | virt-top virt-top 23:46:39 - x86_64 1/1CPU 3392MHz 3816MB1 domains, 1 active, 1 running, 0 sleeping, 0 paused, 0 inactive D:0 O:0 X:0CPU: 5.6% Mem: 2024 MB (2024 MB by guests) ID S RDRQ WRRQ RXBY TXBY %CPU %MEM TIME NAME 1 R 0 1 52 0 5.6 53.0 5:16.15 centos-6.8 |
在开始案例之前,需要知道的必要信息,宿主机IP是192.168.2.200,操作系统版本Centos-6.6-x68_64。
启动虚拟网卡
1 | ifup eth0 |
这里网卡是NAT模式,可以上网,ping通其他机器,但是其他机器无法登陆!
宿主机查看网卡信息
1 | brctl show ifconfig virbr0 ifconfig vnet0 |
实现网桥,在kvm宿主机完成
1 | brctl addbr br0 #创建一个网桥 brctl show #显示网桥信息 brctl addif br0 eth0 && ip addr del dev eth0 192.168.2.200/24 && ifconfig br0 192.168.2.200/24 up brctl show #查看结果ifconfig br0 #验证br0是否成功取代了eth0的IP |
注意: 这里的IP地址为 宿主机ip
1 | virsh list --all ps aux |grep kvm virsh stop Centos-6.6-x68_64 virsh list --all |
修改虚拟机桥接到宿主机,修改52行type为bridge,第54行bridge为br0
1 | # virsh edit Centos-6.6-x68_64 # 命令 52 <interface type='network'> 53 <mac address='52:54:00:2a:2d:60'/> 54 <source network='default'/> 55 56 </interface> 修改为:52 <interface type='bridge'> 53 <mac address='52:54:00:2a:2d:60'/> 54 <source bridge='br0'/> 55 56 </interface> |
启动虚拟机,看到启动前后,桥接变化,vnet0被桥接到了br0
启动前:
1 | # brctl showbridge name bridge id STP enabled interfacesbr0 8000.000c29f824c9 no eth0virbr0 8000.525400353d8e yes virbr0-nic |
启动后:
1 | # virsh start CentOS-6.6-x86_64Domain CentOS-6.6-x86_64 started # brctl show bridge name bridge id STP enabled interfacesbr0 8000.000c29f824c9 no eth0 vnet0virbr0 8000.525400353d8e yes virbr0-nic |
Vnc登陆后,修改ip地址,看到dhcp可以使用,被桥接到现有的ip段,ip是自动获取,而且是和宿主机在同一个IP段.
1 | # ifup eth0 |
从宿主机登陆此服务器,可以成功。
1 | # ssh 192.168.2.108root@192.168.2.108's password: Last login: Sat Jan 30 12:40:28 2016 |
从同一网段其他服务器登陆此虚拟机,也可以成功,至此让kvm管理的服务器能够桥接上网就完成了,在生产环境中,桥接上网是非常必要的。
通过kvm相关的命令来创建虚拟机,安装和调试是非常必要的,因为现有的很多私有云,公有云产品都使用到了kvm这样的技术,学习基本的kvm使用对维护openstack集群有非常要的作用,其次所有的openstack image制作也得通过kvm这样的底层技术来完成,最后上传到openstack的镜像管理模块,才能开始通过openstack image生成云主机。
到此,各位应该能够体会到,其实kvm是一个非常底层和核心的虚拟化技术,而openstack就是对kvm这样的技术进行了一个上层封装,可以非常方便,可视化的操作和维护kvm虚拟机,这就是现在牛上天的云计算技术最底层技术栈,具体怎么实现请看下图。
如上图,没有openstack我们依然可以通过,libvirt来对虚拟机进行操作,只不过比较繁琐和难以维护。通过openstack就可以非常方便的进行底层虚拟化技术的管理、维护、使用。
微信公众号【程序员黄小斜】新生代青年聚集地,程序员成长充电站。作者黄小斜,职业是阿里程序员,身份是斜杠青年,希望和更多的程序员交朋友,一起进步和成长!这一次,我们一起出发。
关注公众号后回复“2019”领取我这两年整理的学习资料,涵盖自学编程、求职面试、算法刷题、Java技术、计算机基础和考研等8000G资料合集。
微信公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,专注于 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
关注公众号后回复“PDF”即可领取200+页的《Java工程师面试指南》强烈推荐,几乎涵盖所有Java工程师必知必会的知识点。
内核,是指的操作系统内核。
所有的操作系统都有内核,无论是Windows还是Linux,都管理着三个重要的资源:计算,网络,存储。
计算指CPU和内存,网络即网络设备,存储即硬盘之类的。
内核是个大管家,想象你的机器上跑着很多的程序,有word,有excel,看着视频,听着音乐,每个程序都要使用CPU和内存,都要上网,都要存硬盘,如果没有一个大管家管着,大家随便用,就乱了。所以需要管家来协调调度整个资源,谁先用,谁后用,谁用多少,谁放在这里,谁放在那里,都需要管家操心。
所以在这个计算机大家庭里面,管家有着比普通的程序更高的权限,运行在内核态,而其他的普通程序运行在用户态,用户态的程序一旦要申请公共的资源,就需要向管家申请,管家帮它分配好,它才能用。
为了区分内核态和用户态,CPU专门设置四个特权等级0,1,2,3 来做这个事情。
当时写Linux内核的时候,估计大牛们还不知道将来虚拟机会大放异彩,大牛们想,一共两级特权,一个内核态,一个用户态,却有四个等级,好奢侈,好富裕,就敞开了用,内核态运行在第0等级,用户态运行在第3等级,占了两头,太不会过日子了。
大牛们在写Linux内核的时候,如果用户态程序做事情,就将扳手掰到第3等级,一旦要申请使用更多的资源,就需要申请将扳手掰到第0等级,内核才能在高权限访问这些资源,申请完资源,返回到用户态,扳手再掰回去。
这个程序一直非常顺利的运行着,直到虚拟机的出现。
如果大家用过Vmware桌面版,或者Virtualbox桌面版,你可以用这个虚拟化软件创建虚拟机,在虚拟机里面安装一个Linux或者windows,外面的操作系统也可以是Linux或者Windows。
当你使用虚拟机软件的时候,和你的excel一样,都是在你的任务栏里面并排的放着,是一个普通的应用。
当你进入虚拟机的时候,虚拟机里面的excel也是一个普通的应用。
但是当你设身处地的站在虚拟机里面的内核的角度思考一下人生,你就困惑了,我到底个啥?
在硬件上的操作系统来看,我是一个普通的应用,只能运行在用户态。可是大牛们生我的时候,我的每一行代码,都告诉我,我是个内核啊,应该运行在内核态,当虚拟机里面的excel要访问网络的时候,向我请求,我的代码就要努力的去操作网络资源,我努力,但是我做不到,我没有权限!
我分裂了。
虚拟化层,也就是Vmware或者Virtualbox需要帮我解决这个问题。
第一种方式,完全虚拟化,其实就是骗我。虚拟化软件模拟假的CPU,内存,网络,硬盘给我,让我自我感觉良好,终于又像个内核了。
真正的工作模式是这样的。
虚拟机内核:我要在CPU上跑一个指令!
虚拟化软件:没问题,你是内核嘛,可以跑
虚拟化软件转过头去找物理机内核:报告管家,我管理的虚拟机里面的一个要执行一个CPU指令,帮忙来一小段时间空闲的CPU时间,让我代他跑个指令。
物理机内核:你等着,另一个跑着呢。好嘞,他终于跑完了,该你了。
虚拟化软件:我代他跑,终于跑完了,出来结果了
虚拟化软件转头给虚拟机内核:哥们,跑完了,结果是这个,我说你是内核吧,绝对有权限,没问题,下次跑指令找我啊。
虚拟机内核:看来我真的是内核呢。可是哥,好像这点指令跑的有点慢啊。
虚拟化软件:这就不错啦,好几个排着队跑呢。
内存的申请模式如下。
虚拟机内核:我启动需要4G内存,我好分给我上面的应用。
虚拟化软件:没问题,才4G,你是内核嘛,马上申请好。
虚拟化软件转头给物理机内核:报告,管家,我启动了一个虚拟机,需要4G内存,给我4个房间呗。
物理机内核:怎么又一个虚拟机啊,好吧,给你90,91,92,93四个房间。
虚拟化软件转头给虚拟机内核:哥们,内存有了,0,1,2,3这个四个房间都是你的,你看,你是内核嘛,独占资源,从0编号的就是你的。
虚拟机内核:看来我真的是内核啊,能从头开始用。那好,我就在房间2的第三个柜子里面放个东西吧。
虚拟化软件:要放东西啊,没问题。心里想:我查查看,这个虚拟机是90号房间开头的,他要在房间2放东西,那就相当于在房间92放东西。
虚拟化软件转头给物理机内核:报告,管家,我上面的虚拟机要在92号房间的第三个柜子里面放个东西。
好了,说完了CPU和内存的例子,不细说网络和硬盘了,也是类似,都是虚拟化软件模拟一个给虚拟机内核看的,其实啥事儿都需要虚拟化软件转一遍。
这种方式一个坏处,就是慢,往往慢到不能忍受。
于是虚拟化软件想,我能不能不当传话筒,还是要让虚拟机内核正视自己的身份,别说你是内核,你还真喘上了,你不是物理机,你是虚拟机。
但是怎么解决权限等级的问题呢?于是Intel的VT-x和AMD的AMD-V从硬件层面帮上了忙。当初谁让你们这些写内核的大牛用等级这么奢侈,用完了0,就是3,也不省着点用,没办法,只好另起炉灶弄一个新的标志位,表示当前是在虚拟机状态下,还是真正的物理机内核下。
对于虚拟机内核来讲,只要将标志位设为虚拟机状态,则可以直接在CPU上执行大部分的指令,不需要虚拟化软件在中间转述,除非遇到特别敏感的指令,才需要将标志位设为物理机内核态运行,这样大大提高了效率。
所以安装虚拟机的时候,务必要将物理CPU的这个标志位打开,是否打开对于Intel可以查看grep “vmx” /proc/cpuinfo,对于AMD可以查看grep “svm” /proc/cpuinfo
这叫做硬件辅助虚拟化。
另外就是访问网络或者硬盘的时候,为了取得更高的性能,也需要让虚拟机内核加载特殊的驱动,也是让虚拟机内核从代码层面就重新定位自己的身份,不能像访问物理机一样访问网络或者硬盘,而是用一种特殊的方式:我知道我不是物理机内核,我知道我是虚拟机,我没那么高的权限,我很可能和很多虚拟机共享物理资源,所以我要学会排队,我写硬盘其实写的是一个物理机上的文件,那我的写文件的缓存方式是不是可以变一下,我发送网络包,根本就不是发给真正的网络设备,而是给虚拟的设备,我可不可以直接在内存里面拷贝给他,等等等等。
一旦我知道我不是物理机内核,痛定思痛,只好重新认识自己,反而能找出很多方式来优化我的资源访问。
这叫做类虚拟化或者半虚拟化。
如果您想更技术的了解本文背后的原理,请看书《系统虚拟化——原理与实现》
微信公众号【程序员黄小斜】新生代青年聚集地,程序员成长充电站。作者黄小斜,职业是阿里程序员,身份是斜杠青年,希望和更多的程序员交朋友,一起进步和成长!这一次,我们一起出发。
关注公众号后回复“2019”领取我这两年整理的学习资料,涵盖自学编程、求职面试、算法刷题、Java技术、计算机基础和考研等8000G资料合集。
微信公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,专注于 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
关注公众号后回复“PDF”即可领取200+页的《Java工程师面试指南》强烈推荐,几乎涵盖所有Java工程师必知必会的知识点。
作者简介:刘超,网易云解决方案首席架构师。10年云计算领域研发及架构经验,Open DC/OS贡献者。长期专注于kubernetes, OpenStack、Hadoop、Docker、Lucene、Mesos等开源软件的企业级应用及产品化。曾出版《Lucene应用开发揭秘》。
以下为正文:
云计算主要解决了四个方面的内容:计算,网络,存储,应用。
计算就是CPU和内存,例如“1+1”这个最简单的算法就是把“1”放在内存里面,然后CPU做加法,返回的结果“2”又保存在内存里面。网络就是你插根网线能上网。存储就是你下个电影有地方放。本次讨论就是围绕这四个部分来讲的。其中,计算、网络、存储三个是IaaS层面,应用是PaaS层面。
云计算整个发展过程,用一句话来形容,就是“分久必合,合久必分”。
在互联网发展初期,大家都爱用物理设备:
部署应用直接使用物理机,看起来很爽,有种土豪的感觉,却有大大的缺点:
因为物理设备的以上缺点,就有了第一次“合久必分”的过程,叫做虚拟化。所谓虚拟化,就是把实的变成虚的:
虚拟化很好地解决了在物理设备阶段存在的三个问题:
在虚拟化阶段,领跑者是Vmware,可以实现基本的计算、网络、存储的虚拟化。
如同这个世界有闭源就有开源、有windows就有linux、有Apple就有Android一样,有Vmware,就有Xen和KVM。
在开源虚拟化方面,Xen 的Citrix做的不错,后来Redhat在KVM发力不少;对于网络虚拟化,有Openvswitch,可以通过命令创建网桥、网卡、设置VLAN、设置带宽;对于存储虚拟化,本地盘有LVM,可以将多个硬盘变成一大块盘,然后在里面切出一小块给用户。
但是虚拟化也有缺点。通过虚拟化软件创建虚拟机,需要人工指定放在哪台机器上、硬盘放在哪个存储设备上,网络的VLAN ID、带宽的具体配置等,都需要人工指定。所以仅使用虚拟化的运维工程师往往有一个Excel表格,记录有多少台物理机,每台机器部署了哪些虚拟机。受此限制,一般虚拟化的集群数目都不是特别大。
为了解决虚拟化阶段遗留的问题,于是有了分久必合的过程。这个过程我们可以形象地称为池化。
虚拟化将资源分得很细,但是如此细分的资源靠Excel去管理,成本太高。池化就是将资源打成一个大的池,当需要资源的时候,帮助用户自动地选择,而非用户指定。这个阶段的关键点:调度器Scheduler。
这样,Vmware有了自己的Vcloud;也有了基于Xen和KVM的私有云平台CloudStack(后来Citrix将其收购后开源)。
当这些私有云平台在用户的数据中心里卖得奇贵无比、赚得盆满钵盈的时候,有其他的公司开始了另外的选择。这就是AWS和Google,他们开始了公有云领域的探索。
AWS最初就是基于Xen技术进行虚拟化的,并且最终形成了公有云平台。也许AWS最初只是不想让自己的电商领域的利润全部交给私有云厂商吧,所以自己的云平台首先支撑起了自己的业务。在这个过程中,AWS严肃地使用了自己的云计算平台,使得公有云平台并不是对资源的配置更加友好,而是对应用的部署更加友好,最终大放异彩。
如果仔细观察就会发现,私有云和公有云虽然使用的是类似的技术,但在产品设计上却是完全不同的两种生物。
私有云厂商和公有云厂商也拥有类似的技术,但在产品运营上呈现出完全不同的基因。
私有云厂商是卖资源的,所以往往在卖私有云平台的时候伴随着卖计算、网络、存储设备。在产品设计上,私有云厂商往往会对客户强调其几乎不会使用的计算、网络、存储的技术参数,因为这些参数可以在和友商对标的过程中占尽优势。私有云的厂商几乎没有自己的大规模应用,所以私有云厂商的平台做出来是给别人用的,自己不会大规模使用,所以产品往往围绕资源展开,而不会对应用的部署友好。
公有云的厂商往往都是有自己大规模的应用需要部署,所以其产品的设计可以将常见的应用部署需要的模块作为组件提供出来,用户可以像拼积木一样,拼接一个适用于自己应用的架构。公有云厂商不必关心各种技术参数的PK,不必关心是否开源,是否兼容各种虚拟化平台,是否兼容各种服务器设备、网络设备、存储设备。你管我用什么,客户部署应用方便就好。
公有云的第一名AWS活的自然很爽,作为第二名Rackspace就不那么舒坦了。
没错,互联网行业基本上就是一家独大,那第二名如何逆袭呢?开源是很好的办法,让整个行业一起为这个云平台出力。于是Rackspace与美国航空航天局(NASA)合作创始了开源云平台OpenStack。
OpenStack现在发展的和AWS有点像了,所以从OpenStack的模块组成可以看到云计算池化的方法。
有了OpenStack,所有的私有云厂商都疯了,原来VMware在私有云市场赚的实在太多了,眼巴巴的看着,没有对应的平台可以和他抗衡。现在有了现成的框架,再加上自己的硬件设备,几乎所有的IT厂商巨头,全部都加入到社区里,将OpenStack开发为自己的产品,连同硬件设备一起,杀入私有云市场。
网易云当然也没有错过这次风口,上线了自己的OpenStack集群,网易云基于OpenStack自主研发了IaaS服务,在计算虚拟化方面,通过裁剪KVM镜像,优化虚拟机启动流程等改进,实现了虚拟机的秒级别启动。在网络虚拟化方面,通过SDN和Openvswitch技术,实现了虚拟机之间的高性能互访。在存储虚拟化方面,通过优化Ceph存储,实现高性能云盘。
但是网易云并没有杀进私有云市场,而是使用OpenStack支撑起了自己的应用,这是互联网的思维。而仅仅是资源层面弹性是不够的,还需要开发出对应用部署友好的组件。例如数据库,负载均衡,缓存等,这些都是应用部署必不可少的,也是网易云在大规模应用实践中,千锤百炼过的。这些组件称为PaaS。
前面一直在讲IaaS层的故事,也即基础设施即服务,基本上在谈计算、网络、存储的事情。现在应该说说应用层,即PaaS层的事情了。
IaaS的定义比较清楚,PaaS的定义就没那么清楚了。有人把数据库、负载均衡、缓存作为PaaS服务;有人把大数据Hadoop,、Spark平台作为PaaS服务;还有人将应用的安装与管理,例如Puppet、 Chef,、Ansible作为PaaS服务。
其实PaaS主要用于管理应用层。我总结为两部分:一部分是你自己的应用应当自动部署,比如Puppet、Chef、Ansible、 Cloud Foundry等,可以通过脚本帮你部署;另一部分是你觉得复杂的通用应用不用部署,比如数据库、缓存、大数据平台,可以在云平台上一点即得。
要么就是自动部署,要么就是不用部署,总的来说就是应用层你也少操心,就是PaaS的作用。当然最好还是都不用去部署,一键可得,所以公有云平台将通用的服务都做成了PaaS平台。另一些你自己开发的应用,除了你自己其他人不会知道,所以你可以用工具变成自动部署。
PaaS最大的优点,就是可以实现应用层的弹性伸缩。比如在双十一期间,10个节点要变成100个节点,如果使用物理设备,再买90台机器肯定来不及,仅仅有IaaS实现资源的弹性是不够的,再创建90台虚拟机,也是空的,还是需要运维人员一台一台地部署。所以有了PaaS就好了,一台虚拟机启动后,马上运行自动部署脚本,进行应用的安装,90台机器自动安装好了应用,才是真正的弹性伸缩。
当然这种部署方式也有一个问题,就是无论Puppet、 Chef、Ansible把安装脚本抽象的再好,说到底也是基于脚本的,然而应用所在的环境千差万别。文件路径的差别,文件权限的差别,依赖包的差别,应用环境的差别,Tomcat、 PHP、 Apache等软件版本的差别,JDK、Python等版本的差别,是否安装了一些系统软件,是否占用了哪些端口,都可能造成脚本执行的不成功。所以看起来是一旦脚本写好,就能够快速复制了,但是环境稍有改变,就需要把脚本进行新一轮的修改、测试、联调。例如在数据中心写好的脚本移到AWS上就不一定直接能用,在AWS上联调好了,迁移到Google Cloud上也可能会再出问题。
于是容器便应运而生。容器是Container,Container另一个意思是集装箱,其实容器的思想就是要变成软件交付的集装箱。集装箱的特点,一是打包,二是标准。设想没有集装箱的时代,如果将货物从A运到B,中间要经过三个码头,换三次船的话,货物每次都要卸下船来,摆的七零八落,然后换船的时候,需要重新摆放整齐,在没有集装箱的时候,船员们都需要在岸上待几天再走。而在有了集装箱后,所有的货物都打包在一起了,并且集装箱的尺寸全部一致,所以每次换船的时候,整体一个箱子搬过去就可以了,小时级别就能完成,船员再也不用长时间上岸等待了。
设想A就是程序员,B就是用户,货物就是代码及运行环境,中间的三个码头分别是开发,测试,上线。
假设代码的运行环境如下:
看,一个简单的Java网站,就需要考虑这么多零零散散的东西,如果不打包,就需要在开发,测试,生产的每个环境上查看,保证环境的一致,甚至要将这些环境重新搭建一遍,就像每次将货物打散了重装一样麻烦。中间稍有差池,比如开发环境用了JDK 1.8,而线上是JDK 1.7;比如开发环境用了root用户,线上需要使用hadoop用户,都可能导致程序的运行失败。
云计算的前世今生(上)中提到:云计算解决了基础资源层的弹性伸缩,却没有解决PaaS层应用随基础资源层弹性伸缩而带来的批量、快速部署问题。于是容器应运而生。
容器是Container,Container另一个意思是集装箱,其实容器的思想就是要变成软件交付的集装箱。集装箱的特点,一是打包,二是标准。

在没有集装箱的时代,假设将货物从A运到B,中间要经过三个码头、换三次船。每次都要将货物卸下船来,摆的七零八落,然后搬上船重新整齐摆好。因此在没有集装箱的时候,每次换船,船员们都要在岸上待几天才能走。

有了集装箱以后,所有的货物都打包在一起了,并且集装箱的尺寸全部一致,所以每次换船的时候,一个箱子整体搬过去就行了,小时级别就能完成,船员再也不能上岸长时间耽搁了。这是集装箱“打包”、“标准”两大特点在生活中的应用。下面用一个简单的案例来看看容器在开发部署中的实际应用。
假设有一个简单的Java网站需要上线,代码的运行环境如下:

看,一个简单的Java网站,就有这么多零零散散的东西!这就像很多零碎地货物,如果不打包,就需要在开发、测试、生产的每个环境上重新查看以保证环境的一致,有时甚至要将这些环境重新搭建一遍,就像每次将货物卸载、重装一样麻烦。中间稍有差池,比如开发环境用了JDK 1.8,而线上是JDK 1.7;比如开发环境用了root用户,线上需要使用hadoop用户,都可能导致程序的运行失败。
那么容器如何对应用打包呢?还是要学习集装箱,首先要有个封闭的环境,将货物封装起来,让货物之间互不干扰,互相隔离,这样装货卸货才方便。好在ubuntu中的lxc技术早就能做到这一点。
封闭的环境主要使用了两种技术,一种是看起来是隔离的技术,称为namespace,也即每个namespace中的应用看到的是不同的IP地址、用户空间、程号等。另一种是用起来是隔离的技术,称为cgroup,也即明明整台机器有很多的CPU、内存,而一个应用只能用其中的一部分。有了这两项技术,集装箱的铁盒子我们是焊好了,接下来是决定往里面放什么。
最简单粗暴的方法,就是将上面列表中所有的都放到集装箱里面。但是这样太大了!因为即使你安装一个干干静静的ubuntu操作系统,什么都不装,就很大了。把操作系统装进容器相当于把船也放到了集装箱里面!传统的虚拟机镜像就是这样的,动辄几十G。答案当然是NO!所以第一项操作系统不能装进容器。
撇下第一项操作系统,剩下的所有的加起来,也就几百M,就轻便多了。因此一台服务器上的容器是共享操作系统内核的,容器在不同机器之间的迁移不带内核,这也是很多人声称容器是轻量级的虚拟机的原因。轻不白轻,自然隔离性就差了,一个容器让操作系统崩溃了,其他容器也就跟着崩溃了,这相当于一个集装箱把船压漏水了,所有的集装箱一起沉。
另一个需要撇下的就是随着应用的运行而产生并保存在本地的数据。这些数据多以文件的形式存在,例如数据库文件、文本文件。这些文件会随着应用的运行,越来越大,如果这些数据也放在容器里面,会让容器变得很大,影响容器在不同环境的迁移。而且这些数据在开发、测试、线上环境之间的迁移是没有意义的,生产环境不可能用测试环境的文件,所以往往这些数据也是保存在容器外面的存储设备上。也是为什么人们称容器是无状态的。
至此集装箱焊好了,货物也装进去了,接下来就是如何将这个集装箱标准化,从而在哪艘船上都能运输。这里的标准一个是镜像,一个是容器的运行环境。
所谓的镜像,就是将你焊好集装箱的那个时刻,将集装箱的状态保存下来,就像孙悟空说定,集装箱里面就定在了那一刻,然后将这一刻的状态保存成一系列文件。这些文件的格式是标准的,谁看到这些文件,都能还原当时定住的那个时刻。将镜像还原成运行时的过程(就是读取镜像文件,还原那个时刻的过程)就是容器的运行的过程。除了大名鼎鼎的Docker,还有其他的容器,例如AppC、Mesos Container,都能运行容器镜像。所以说容器不等于Docker。
总而言之,容器是轻量级的、隔离差的、适用于无状态的,可以基于镜像标准实现跨主机、跨环境的随意迁移。
有了容器,使得PaaS层对于用户自身应用的自动部署变得快速而优雅。容器快,快在了两方面,第一是虚拟机启动的时候要先启动操作系统,容器不用启动操作系统,因为是共享内核的。第二是虚拟机启动后使用脚本安装应用,容器不用安装应用,因为已经打包在镜像里面了。所以最终虚拟机的启动是分钟级别,而容器的启动是秒级。容器咋这么神奇。其实一点都不神奇,第一是偷懒少干活了,第二是提前把活干好了。
因为容器的启动快,人们往往不会创建一个个小的虚拟机来部署应用,因为这样太费时间了,而是创建一个大的虚拟机,然后在大的虚拟机里面再划分容器,而不同的用户不共享大的虚拟机,可以实现操作系统内核的隔离。这又是一次合久必分的过程。由IaaS层的虚拟机池,划分为更细粒度的容器池。
有了容器的管理平台,又是一次分久必合的过程。
容器的粒度更加细,管理起来更难管,甚至是手动操作难以应对的。假设你有100台物理机,其实规模不是太大,用Excel人工管理是没问题的,但是一台上面开10台虚拟机,虚拟机的个数就是1000台,人工管理已经很困难了,但是一台虚拟机里面开10个容器,就是10000个容器,你是不是已经彻底放弃人工运维的想法了。
所以容器层面的管理平台是一个新的挑战,关键字就是自动化:
自发现:容器与容器之间的相互配置还能像虚拟机一样,记住IP地址,然后互相配置吗?这么多容器,你怎么记得住一旦一台虚拟机挂了重启,IP改变,应该改哪些配置,列表长度至少万行级别的啊。所以容器之间的配置通过名称来的,无论容器跑到哪台机器上,名称不变,就能访问到。
自修复:容器挂了,或是进程宕机了,能像虚拟机那样,登陆上去查看一下进程状态,如果不正常重启一下么?你要登陆万台docker了。所以容器的进程挂了,容器就自动挂掉了,然后自动重启。
弹性自伸缩 Auto Scaling:当容器的性能不足的时候,需要手动伸缩,手动部署么?当然也要自动来。
当前火热的容器管理平台有三大流派:
一个是Kubernetes,我们称为段誉型。段誉(Kubernetes)的父亲(Borg)武功高强,出身皇族(Google),管理过偌大的一个大理国(Borg是Google数据中心的容器管理平台)。作为大理段式后裔,段誉的武功基因良好(Kubernetes的理念设计比较完善),周围的高手云集,习武环境也好(Kubernetes生态活跃,热度高),虽然刚刚出道的段誉武功不及其父亲,但是只要跟着周围的高手不断切磋,武功既可以飞速提升。
一个是Mesos,我们称为乔峰型。乔峰(Mesos)的主要功夫降龙十八掌(Mesos的调度功能)独步武林,为其他帮派所无。而且乔峰也管理过人数众多的丐帮(Mesos管理过Tweeter的容器集群)。后来乔峰从丐帮出来,在江湖中特例独行(Mesos的创始人成立了公司Mesosphere)。乔峰的优势在于,乔峰的降龙十八掌(Mesos)就是在丐帮中使用的降龙十八掌,相比与段誉初学其父的武功来说,要成熟很多。但是缺点是,降龙十八掌只掌握在少数的几个丐帮帮主手中(Mesos社区还是以Mesosphere为主导),其他丐帮兄弟只能远远崇拜乔峰,而无法相互切磋(社区热度不足)。
一个是Swarm,我们称为慕容型。慕容家族(Swarm是Docker家族的集群管理软件)的个人功夫是非常棒的(Docker可以说称为容器的事实标准),但是看到段誉和乔峰能够管理的组织规模越来越大,有一统江湖的趋势,着实眼红了,于是开始想创建自己的慕容鲜卑帝国(推出Swarm容器集群管理软件)。但是个人功夫好,并不代表着组织能力强(Swarm的集群管理能力),好在慕容家族可以借鉴段誉和乔峰的组织管理经验,学习各家公司,以彼之道,还施彼身,使得慕容公子的组织能力(Swarm借鉴了很多前面的集群管理思想)也在逐渐的成熟中。
三大容器门派,到底鹿死谁手,谁能一统江湖,尚未可知。
网易之所以选型Kubernetes作为自己的容器管理平台,是因为基于 Borg 成熟的经验打造的 Kubernetes,为容器编排管理提供了完整的开源方案,并且社区活跃,生态完善,积累了大量分布式、服务化系统架构的最佳实践。
想不想尝试一下最先进的容器管理平台呢?我们先了解一下Docker的生命周期。如图所示。
图中最中间就是最核心的两个部分,一个是镜像Images,一个是容器Containers。镜像运行起来就是容器。容器运行的过程中,基于原始镜像做了改变,比如安装了程序,添加了文件,也可以提交回去(commit)成为镜像。如果大家安装过系统,镜像有点像GHOST镜像,从GHOST镜像安装一个系统,运行起来,就相当于容器;容器里面自带应用,就像GHOST镜像安装的系统里面不是裸的操作系统,里面可能安装了微信,QQ,视频播放软件等。安装好的系统使用的过程中又安装了其他的软件,或者下载了文件,还可以将这个系统重新GHOST成一个镜像,当其他人通过这个镜像再安装系统的时候,则其他的软件也就自带了。
普通的GHOST镜像就是一个文件,但是管理不方便,比如如果有十个GHOST镜像的话,你可能已经记不清楚哪个镜像里面安装了哪个版本的软件了。所以容器镜像有tag的概念,就是一个标签,比如dev-1.0,dev-1.1,production-1.1等,凡是能够帮助你区分不同镜像的,都可以。为了镜像的统一管理,有一个镜像库的东西,可以通过push将本地的镜像放到统一的镜像库中保存,可以通过pull将镜像库中的镜像拉到本地来。
从镜像运行一个容器可使用下面的命令,如果初步使用Docker,记下下面这一个命令就可以了。
这行命令会启动一个里面安装了mysql的容器。其中docker run就是运行一个容器;–name就是给这个容器起个名字;-v 就是挂数据盘,将外面的一个目录/my/own/datadir挂载到容器里面的一个目录/var/lib/mysql作为数据盘,外面的目录是在容器所运行的主机上的,也可以是远程的一个云盘;-e 是设置容器运行环境的环境变量,环境变量是最常使用的设置参数的方式,例如这里设置mysql的密码。mysql:tag就是镜像的名字和标签。
docker stop可以停止这个容器,start可以再启动这个容器,restart可以重启这个容器。在容器内部做了改变,例如安装了新的软件,产生了新的文件,则调用docker commit变成新的镜像。
镜像生产过程,除了可以通过启动一个docker,手动修改,然后调用docker commit形成新镜像之外,还可以通过书写Dockerfile,通过docker build来编译这个Dockerfile来形成新镜像。为什么要这样做呢?前面的方式太不自动化了,需要手工干预,而且还经常会忘了手工都做了什么。用Dockerfile可以很好的解决这个问题。
Dockerfile的一个简单的例子如下:
这其实是一个镜像的生产说明书,Docker build的过程就是根据这个生产说明书来生产镜像:
FROM基础镜像,先下载这个基础镜像,然后从这个镜像启动一个容器,并且登陆到容器里面;
RUN运行一个命令,在容器里面运行这个命令;
COPY/ADD将一些文件添加到容器里面;
最终给容器设置启动命令 ENTRYPOINT,这个命令不在镜像生成过程中执行,而是在容器运行的时候作为主程序执行;
将所有的修改commit成镜像。
这里需要说明一下的就是主程序,是Docker里面一个重要的概念,虽然镜像里面可以安装很多的程序,但是必须有一个主程序,主程序和容器的生命周期完全一致,主程序在则容器在,主程序亡则容器亡。
就像图中展示的一样,容器是一个资源限制的框,但是这个框没有底,全靠主进程撑着,主进程挂了,衣服架子倒了,衣服也就垮了。
了解了如何运行一个独立的容器,接下来介绍如何使用容器管理平台。

容器管理平台会对容器做更高的抽象,容器不再是单打独斗,而且组成集团军共同战斗。多个容器组成一个Pod,这几个容器亲如兄弟,干的也是相关性很强的活,能够通过localhost访问彼此,真是兄弟齐心,力可断金。有的任务一帮兄弟还刚不住,就需要多个Pod合力完成,这个由ReplicationController进行控制,可以将一个Pod复制N个副本,同时承载任务,众人拾柴火焰高。
N个Pod如果对外散兵作战,一是无法合力,二是给人很乱的感觉,因而需要有一个老大,作为代言人,将大家团结起来,一致对外,这就是Service。老大对外提供统一的虚拟IP和端口,并将这个IP和服务名关联起来,访问服务名,则自动映射为虚拟IP。老大的意思就是,如果外面要访问我这个团队,喊一声名字就可以,例如”雷锋班,帮敬老院打扫卫生!”,你不用管雷锋班的那个人去打扫卫生,每个人打扫哪一部分,班长会统一分配。
最上层通过namespace分隔完全隔离的环境,例如生产环境,测试环境,开发环境等。就像军队分华北野战军,东北野战军一样。野战军立正,出发,部署一个Tomcat的Java应用。
作者:网易云基础服务
链接:https://www.jianshu.com/p/52312b1eb633
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
微信公众号【程序员黄小斜】新生代青年聚集地,程序员成长充电站。作者黄小斜,职业是阿里程序员,身份是斜杠青年,希望和更多的程序员交朋友,一起进步和成长!这一次,我们一起出发。
关注公众号后回复“2019”领取我这两年整理的学习资料,涵盖自学编程、求职面试、算法刷题、Java技术、计算机基础和考研等8000G资料合集。
微信公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,专注于 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
关注公众号后回复“PDF”即可领取200+页的《Java工程师面试指南》强烈推荐,几乎涵盖所有Java工程师必知必会的知识点。
阅读 1093
收藏 76
2017-08-23
原文链接:www.ruanyifeng.com
9月7日-8日 北京,与 Google Twitch 等团队技术大咖面对面www.bagevent.com
全文搜索属于最常见的需求,开源的 Elasticsearch (以下简称 Elastic)是目前全文搜索引擎的首选。
它可以快速地储存、搜索和分析海量数据。维基百科、Stack Overflow、Github 都采用它。
Elastic 的底层是开源库 Lucene。但是,你没法直接用 Lucene,必须自己写代码去调用它的接口。Elastic 是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用。
本文从零开始,讲解如何使用 Elastic 搭建自己的全文搜索引擎。每一步都有详细的说明,大家跟着做就能学会。
Elastic 需要 Java 8 环境。如果你的机器还没安装 Java,可以参考这篇文章,注意要保证环境变量JAVA_HOME正确设置。
安装完 Java,就可以跟着官方文档安装 Elastic。直接下载压缩包比较简单。
2
>
接着,进入解压后的目录,运行下面的命令,启动 Elastic。
2
>
如果这时报错“max virtual memory areas vm.max_map_count [65530] is too low”,要运行下面的命令。
2
>
如果一切正常,Elastic 就会在默认的9200端口运行。这时,打开另一个命令行窗口,请求该端口,会得到说明信息。
2
>
上面代码中,请求9200端口,Elastic 返回一个 JSON 对象,包含当前节点、集群、版本等信息。
按下 Ctrl + C,Elastic 就会停止运行。
默认情况下,Elastic 只允许本机访问,如果需要远程访问,可以修改 Elastic 安装目录的config/elasticsearch.yml文件,去掉network.host的注释,将它的值改成0.0.0.0,然后重新启动 Elastic。
2
>
上面代码中,设成0.0.0.0让任何人都可以访问。线上服务不要这样设置,要设成具体的 IP。
Elastic 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个 Elastic 实例。
单个 Elastic 实例称为一个节点(node)。一组节点构成一个集群(cluster)。
Elastic 会索引所有字段,经过处理后写入一个反向索引(Inverted Index)。查找数据的时候,直接查找该索引。
所以,Elastic 数据管理的顶层单位就叫做 Index(索引)。它是单个数据库的同义词。每个 Index (即数据库)的名字必须是小写。
下面的命令可以查看当前节点的所有 Index。
2
>
Index 里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。
Document 使用 JSON 格式表示,下面是一个例子。
2
>
同一个 Index 里面的 Document,不要求有相同的结构(scheme),但是最好保持相同,这样有利于提高搜索效率。
Document 可以分组,比如weather这个 Index 里面,可以按城市分组(北京和上海),也可以按气候分组(晴天和雨天)。这种分组就叫做 Type,它是虚拟的逻辑分组,用来过滤 Document。
不同的 Type 应该有相似的结构(schema),举例来说,id字段不能在这个组是字符串,在另一个组是数值。这是与关系型数据库的表的一个区别。性质完全不同的数据(比如products和logs)应该存成两个 Index,而不是一个 Index 里面的两个 Type(虽然可以做到)。
下面的命令可以列出每个 Index 所包含的 Type。
2
>
根据规划,Elastic 6.x 版只允许每个 Index 包含一个 Type,7.x 版将会彻底移除 Type。
新建 Index,可以直接向 Elastic 服务器发出 PUT 请求。下面的例子是新建一个名叫weather的 Index。
2
>
服务器返回一个 JSON 对象,里面的acknowledged字段表示操作成功。
2
>
然后,我们发出 DELETE 请求,删除这个 Index。
2
>
首先,安装中文分词插件。这里使用的是 ik,也可以考虑其他插件(比如 smartcn)。
2
>
上面代码安装的是5.5.1版的插件,与 Elastic 5.5.1 配合使用。
接着,重新启动 Elastic,就会自动加载这个新安装的插件。
然后,新建一个 Index,指定需要分词的字段。这一步根据数据结构而异,下面的命令只针对本文。基本上,凡是需要搜索的中文字段,都要单独设置一下。
2
>
上面代码中,首先新建一个名称为accounts的 Index,里面有一个名称为person的 Type。person有三个字段。
- user
- title
- desc
这三个字段都是中文,而且类型都是文本(text),所以需要指定中文分词器,不能使用默认的英文分词器。
Elastic 的分词器称为 analyzer。我们对每个字段指定分词器。
2
>
上面代码中,analyzer是字段文本的分词器,search_analyzer是搜索词的分词器。ik_max_word分词器是插件ik提供的,可以对文本进行最大数量的分词。
向指定的 /Index/Type 发送 PUT 请求,就可以在 Index 里面新增一条记录。比如,向/accounts/person发送请求,就可以新增一条人员记录。
2
>
服务器返回的 JSON 对象,会给出 Index、Type、Id、Version 等信息。
2
>
如果你仔细看,会发现请求路径是/accounts/person/1,最后的1是该条记录的 Id。它不一定是数字,任意字符串(比如abc)都可以。
新增记录的时候,也可以不指定 Id,这时要改成 POST 请求。
2
>
上面代码中,向/accounts/person发出一个 POST 请求,添加一个记录。这时,服务器返回的 JSON 对象里面,_id字段就是一个随机字符串。
2
>
注意,如果没有先创建 Index(这个例子是accounts),直接执行上面的命令,Elastic 也不会报错,而是直接生成指定的 Index。所以,打字的时候要小心,不要写错 Index 的名称。
向/Index/Type/Id发出 GET 请求,就可以查看这条记录。
2
>
上面代码请求查看/accounts/person/1这条记录,URL 的参数pretty=true表示以易读的格式返回。
返回的数据中,found字段表示查询成功,_source字段返回原始记录。
2
>
如果 Id 不正确,就查不到数据,found字段就是false。
2
>
删除记录就是发出 DELETE 请求。
2
>
这里先不要删除这条记录,后面还要用到。
更新记录就是使用 PUT 请求,重新发送一次数据。
2
>
上面代码中,我们将原始数据从”数据库管理”改成”数据库管理,软件开发”。 返回结果里面,有几个字段发生了变化。
2
>
可以看到,记录的 Id 没变,但是版本(version)从1变成2,操作类型(result)从created变成updated,created字段变成false,因为这次不是新建记录。
使用 GET 方法,直接请求/Index/Type/_search,就会返回所有记录。
2
>
上面代码中,返回结果的 took字段表示该操作的耗时(单位为毫秒),timed_out字段表示是否超时,hits字段表示命中的记录,里面子字段的含义如下。
total:返回记录数,本例是2条。max_score:最高的匹配程度,本例是1.0。hits:返回的记录组成的数组。
返回的记录中,每条记录都有一个_score字段,表示匹配的程序,默认是按照这个字段降序排列。
Elastic 的查询非常特别,使用自己的查询语法,要求 GET 请求带有数据体。
2
>
上面代码使用 Match 查询,指定的匹配条件是desc字段里面包含”软件”这个词。返回结果如下。
2
>
Elastic 默认一次返回10条结果,可以通过size字段改变这个设置。
2
>
上面代码指定,每次只返回一条结果。
还可以通过from字段,指定位移。
2
>
上面代码指定,从位置1开始(默认是从位置0开始),只返回一条结果。
如果有多个搜索关键字, Elastic 认为它们是or关系。
2
>
上面代码搜索的是软件 or 系统。
如果要执行多个关键词的and搜索,必须使用布尔查询。
2
>
(完)

在开发网站/App项目的时候,通常需要搭建搜索服务。比如,新闻类应用需要检索标题/内容,社区类应用需要检索用户/帖子。
对于简单的需求,可以使用数据库的 LIKE 模糊搜索,示例:
SELECT * FROM news WHERE title LIKE ‘%法拉利跑车%’
可以查询到所有标题含有 “法拉利跑车” 关键词的新闻,但是这种方式有明显的弊端:
1、模糊查询性能极低,当数据量庞大的时候,往往会使数据库服务中断;
2、无法查询相关的数据,只能严格在标题中匹配关键词。
因此,需要搭建专门提供搜索功能的服务,具备分词、全文检索等高级功能。 Solr 就是这样一款搜索引擎,可以让你快速搭建适用于自己业务的搜索服务。
到官网 http://lucene.apache.org/solr/ 下载安装包,解压并进入 Solr 目录:
wget ‘http://apache.website-solution.net/lucene/solr/6.2.0/solr-6.2.0.tgz'
tar xvf solr-6.2.0.tgz
cd solr-6.2.0
目录结构如下:

Solr 6.2 目录结构
启动 Solr 服务之前,确认已经安装 Java 1.8 :

查看 Java 版本
启动 Solr 服务:
./bin/solr start -m 1g
Solr 将默认监听 8983 端口,其中 -m 1g 指定分配给 JVM 的内存为 1 G。
在浏览器中访问 Solr 管理后台:

Solr 管理后台
创建 Solr 应用:
./bin/solr create -c my_news
可以在 solr-6.2.0/server/solr 目录下生成 my_news 文件夹,结构如下:

my_news 目录结构
同时,可以在管理后台看到 my_news:

管理后台
我们将从 MySQL 数据库中导入数据到 Solr 并建立索引。
首先,需要了解 Solr 中的两个概念: 字段(field) 和 字段类型(fieldType),配置示例如下:

schema.xml 示例
field 指定一个字段的名称、是否索引/存储和字段类型。
fieldType 指定一个字段类型的名称以及在查询/索引的时候可能用到的分词插件。
将 solr-6.2.0\server\solr\my_news\conf 目录下默认的配置文件 managed-schema 重命名为 schema.xml 并加入新的 fieldType:

分词类型
在 my_news 目录下创建 lib 目录,将用到的分词插件 ik-analyzer-solr5-5.x.jar 加到 lib 目录,结构如下:

my_news 目录结构
在 Solr 安装目录下重启服务:
./bin/solr restart
可以在管理后台看到新加的类型:

text_ik 类型
接下来创建和我们数据库字段对应的 field:title 和 content,类型选为 text_ik:

新建字段 title
将要导入数据的 MySQL 数据库表结构:

编辑 conf/solrconfig.xml 文件,加入类库和数据库配置:

类库

dataimport config
同时新建数据库连接配置文件 conf/db-mysql-config.xml ,内容如下:

数据库配置文件
将数据库连接组件 mysql-connector-java-5.1.39-bin.jar 放到 lib 目录下,重启 Solr,访问管理后台,执行全量导入数据:

全量导入数据
创建定时更新脚本:

定时更新脚本
加入到定时任务,每5分钟增量更新一次索引:

定时任务
在 Solr 管理后台测试搜索结果:

分词搜索结果
至此,基本的搜索引擎搭建完毕,外部应用只需通过 http 协议提供查询参数,就可以获取搜索结果。
通常需要对搜索结果进行人工干预,比如编辑推荐、竞价排名或者屏蔽搜索结果。Solr 已经内置了 QueryElevationComponent 插件,可以从配置文件中获取搜索关键词对应的干预列表,并将干预结果排在搜索结果的前面。
在 solrconfig.xml 文件中,可以看到:

干预其请求配置
定义了搜索组件 elevator,应用在 /elevate 的搜索请求中,干预结果的配置文件在 solrconfig.xml 同目录下的 elevate.xml 中,干预配置示例:

重启 Solr ,当搜索 “关键词” 的时候,id 为 1和 4 的文档将出现在前面,同时 id = 3 的文档被排除在结果之外,可以看到,没有干预的时候,搜索结果为:

无干预结果
当有搜索干预的时候:

干预结果
通过配置文件干预搜索结果,虽然简单,但是每次更新都要重启 Solr 才能生效,稍显麻烦,我们可以仿照 QueryElevationComponent 类,开发自己的干预组件,例如:从 Redis 中读取干预配置。
中文的搜索质量,和分词的效果息息相关,可以在 Solr 管理后台测试分词:

分词结果测试
上例可以看到,使用 IKAnalyzer 分词插件,对 “北京科技大学” 分词的测试结果。当用户搜索 “北京”、“科技大学”、“科技大”、“科技”、“大学” 这些关键词的时候,都会搜索到文本内容含 “北京科技大学” 的文档。
常用的中文分词插件有 IKAnalyzer、mmseg4j和 Solr 自带的 smartcn 等,分词效果各有优劣,具体选择哪个,可以根据自己的业务场景,分别测试效果再选择。
分词插件一般都有自己的默认词库和扩展词库,默认词库包含了绝大多数常用的中文词语。如果默认词库无法满足你的需求,比如某些专业领域的词汇,可以在扩展词库中手动添加,这样分词插件就能识别新词语了。

分词插件扩展词库配置示例
分词插件还可以指定停止词库,将某些无意义的词汇剔出分词结果,比如:“的”、“哼” 等,例如:

去除无意义的词
以上介绍了 Solr 最常用的一些功能,Solr 本身还有很多其他丰富的功能,比如分布式部署。
希望对你有所帮助。
1、参考资料:
http://lucene.apache.org/solr/quickstart.html
https://cwiki.apache.org/confluence/display/solr/Apache+Solr+Reference+Guide
2、上述 Demo 中用到的所有配置文件、Jar 包:
https://github.com/Ceelog/OpenSchool/blob/master/my_news.zip
3、还有疑问?联系作者微博/微信 @Ceelog
微信公众号【程序员黄小斜】新生代青年聚集地,程序员成长充电站。作者黄小斜,职业是阿里程序员,身份是斜杠青年,希望和更多的程序员交朋友,一起进步和成长!这一次,我们一起出发。
关注公众号后回复“2019”领取我这两年整理的学习资料,涵盖自学编程、求职面试、算法刷题、Java技术、计算机基础和考研等8000G资料合集。
微信公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,专注于 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
关注公众号后回复“PDF”即可领取200+页的《Java工程师面试指南》强烈推荐,几乎涵盖所有Java工程师必知必会的知识点。
一、总论
根据lucene.apache.org/java/docs/i…定义:
Lucene是一个高效的,基于Java的全文检索库。
所以在了解Lucene之前要费一番工夫了解一下全文检索。
那么什么叫做全文检索呢?这要从我们生活中的数据说起。
我们生活中的数据总体分为两种:结构化数据和非结构化数据。
当然有的地方还会提到第三种,半结构化数据,如XML,HTML等,当根据需要可按结构化数据来处理,也可抽取出纯文本按非结构化数据来处理。
非结构化数据又一种叫法叫全文数据。
按照数据的分类,搜索也分为两种:
对非结构化数据也即对全文数据的搜索主要有两种方法:
一种是顺序扫描法(Serial Scanning):所谓顺序扫描,比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。如利用windows的搜索也可以搜索文件内容,只是相当的慢。如果你有一个80G硬盘,如果想在上面找到一个内容包含某字符串的文件,不花他几个小时,怕是做不到。Linux下的grep命令也是这一种方式。大家可能觉得这种方法比较原始,但对于小数据量的文件,这种方法还是最直接,最方便的。但是对于大量的文件,这种方法就很慢了。
有人可能会说,对非结构化数据顺序扫描很慢,对结构化数据的搜索却相对较快(由于结构化数据有一定的结构可以采取一定的搜索算法加快速度),那么把我们的非结构化数据想办法弄得有一定结构不就行了吗?
这种想法很天然,却构成了全文检索的基本思路,也即将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。
这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
这种说法比较抽象,举几个例子就很容易明白,比如字典,字典的拼音表和部首检字表就相当于字典的索引,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。然而字的某些信息可以提取出来进行结构化处理,比如读音,就比较结构化,分声母和韵母,分别只有几种可以一一列举,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据——也即对字的解释。
这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
下面这幅图来自《Lucene in action》,但却不仅仅描述了Lucene的检索过程,而是描述了全文检索的一般过程。

全文检索大体分两个过程,索引创建(Indexing)和搜索索引(Search)。
于是全文检索就存在三个重要问题:
索引里面究竟存些什么?(Index)
如何创建索引?(Indexing)
如何对索引进行搜索?(Search)
下面我们顺序对每个个问题进行研究。
索引里面究竟需要存些什么呢?
首先我们来看为什么顺序扫描的速度慢:
其实是由于我们想要搜索的信息和非结构化数据中所存储的信息不一致造成的。
非结构化数据中所存储的信息是每个文件包含哪些字符串,也即已知文件,欲求字符串相对容易,也即是从文件到字符串的映射。而我们想搜索的信息是哪些文件包含此字符串,也即已知字符串,欲求文件,也即从字符串到文件的映射。两者恰恰相反。于是如果索引总能够保存从字符串到文件的映射,则会大大提高搜索速度。
由于从字符串到文件的映射是文件到字符串映射的反向过程,于是保存这种信息的索引称为反向索引。
反向索引的所保存的信息一般如下:
假设我的文档集合里面有100篇文档,为了方便表示,我们为文档编号从1到100,得到下面的结构

左边保存的是一系列字符串,称为词典。
每个字符串都指向包含此字符串的文档(Document)链表,此文档链表称为倒排表(Posting List)。
有了索引,便使保存的信息和要搜索的信息一致,可以大大加快搜索的速度。
比如说,我们要寻找既包含字符串“lucene”又包含字符串“solr”的文档,我们只需要以下几步:
1. 取出包含字符串“lucene”的文档链表。
2. 取出包含字符串“solr”的文档链表。
3. 通过合并链表,找出既包含“lucene”又包含“solr”的文件。

看到这个地方,有人可能会说,全文检索的确加快了搜索的速度,但是多了索引的过程,两者加起来不一定比顺序扫描快多少。的确,加上索引的过程,全文检索不一定比顺序扫描快,尤其是在数据量小的时候更是如此。而对一个很大量的数据创建索引也是一个很慢的过程。
然而两者还是有区别的,顺序扫描是每次都要扫描,而创建索引的过程仅仅需要一次,以后便是一劳永逸的了,每次搜索,创建索引的过程不必经过,仅仅搜索创建好的索引就可以了。
这也是全文搜索相对于顺序扫描的优势之一:一次索引,多次使用。
全文检索的索引创建过程一般有以下几步:
为了方便说明索引创建过程,这里特意用两个文件为例:
文件一:Students should be allowed to go out with their friends, but not allowed to drink beer.
文件二:My friend Jerry went to school to see his students but found them drunk which is not allowed.
分词组件(Tokenizer)会做以下几件事情(此过程称为Tokenize):
将文档分成一个一个单独的单词。
去除标点符号。
去除停词(Stop word)。
所谓停词(Stop word)就是一种语言中最普通的一些单词,由于没有特别的意义,因而大多数情况下不能成为搜索的关键词,因而创建索引时,这种词会被去掉而减少索引的大小。
英语中挺词(Stop word)如:“the”,“a”,“this”等。
对于每一种语言的分词组件(Tokenizer),都有一个停词(stop word)集合。
经过分词(Tokenizer)后得到的结果称为词元(Token)。
在我们的例子中,便得到以下词元(Token):
“Students”,“allowed”,“go”,“their”,“friends”,“allowed”,“drink”,“beer”,“My”,“friend”,“Jerry”,“went”,“school”,“see”,“his”,“students”,“found”,“them”,“drunk”,“allowed”。
语言处理组件(linguistic processor)主要是对得到的词元(Token)做一些同语言相关的处理。
对于英语,语言处理组件(Linguistic Processor)一般做以下几点:
变为小写(Lowercase)。
将单词缩减为词根形式,如“cars”到“car”等。这种操作称为:stemming。
将单词转变为词根形式,如“drove”到“drive”等。这种操作称为:lemmatization。
Stemming 和 lemmatization的异同:
语言处理组件(linguistic processor)的结果称为词(Term)。
在我们的例子中,经过语言处理,得到的词(Term)如下:
“student”,“allow”,“go”,“their”,“friend”,“allow”,“drink”,“beer”,“my”,“friend”,“jerry”,“go”,“school”,“see”,“his”,“student”,“find”,“them”,“drink”,“allow”。
也正是因为有语言处理的步骤,才能使搜索drove,而drive也能被搜索出来。
索引组件(Indexer)主要做以下几件事情:
1. 利用得到的词(Term)创建一个字典。
在我们的例子中字典如下:
| Term | Document ID |
|---|---|
| student | 1 |
| allow | 1 |
| go | 1 |
| their | 1 |
| friend | 1 |
| allow | 1 |
| drink | 1 |
| beer | 1 |
| my | 2 |
| friend | 2 |
| jerry | 2 |
| go | 2 |
| school | 2 |
| see | 2 |
| his | 2 |
| student | 2 |
| find | 2 |
| them | 2 |
| drink | 2 |
| allow | 2 |
| Term | Document ID |
|---|---|
| allow | 1 |
| allow | 1 |
| allow | 2 |
| beer | 1 |
| drink | 1 |
| drink | 2 |
| find | 2 |
| friend | 1 |
| friend | 2 |
| go | 1 |
| go | 2 |
| his | 2 |
| jerry | 2 |
| my | 2 |
| school | 2 |
| see | 2 |
| student | 1 |
| student | 2 |
| their | 1 |
| them | 2 |

在此表中,有几个定义:
所以对词(Term) “allow”来讲,总共有两篇文档包含此词(Term),从而词(Term)后面的文档链表总共有两项,第一项表示包含“allow”的第一篇文档,即1号文档,此文档中,“allow”出现了2次,第二项表示包含“allow”的第二个文档,是2号文档,此文档中,“allow”出现了1次。
到此为止,索引已经创建好了,我们可以通过它很快的找到我们想要的文档。
而且在此过程中,我们惊喜地发现,搜索“drive”,“driving”,“drove”,“driven”也能够被搜到。因为在我们的索引中,“driving”,“drove”,“driven”都会经过语言处理而变成“drive”,在搜索时,如果您输入“driving”,输入的查询语句同样经过我们这里的一到三步,从而变为查询“drive”,从而可以搜索到想要的文档。
到这里似乎我们可以宣布“我们找到想要的文档了”。
然而事情并没有结束,找到了仅仅是全文检索的一个方面。不是吗?如果仅仅只有一个或十个文档包含我们查询的字符串,我们的确找到了。然而如果结果有一千个,甚至成千上万个呢?那个又是您最想要的文件呢?
打开Google吧,比如说您想在微软找份工作,于是您输入“Microsoft job”,您却发现总共有22600000个结果返回。好大的数字呀,突然发现找不到是一个问题,找到的太多也是一个问题。在如此多的结果中,如何将最相关的放在最前面呢?

当然Google做的很不错,您一下就找到了jobs at Microsoft。想象一下,如果前几个全部是“Microsoft does a good job at software industry…”将是多么可怕的事情呀。
如何像Google一样,在成千上万的搜索结果中,找到和查询语句最相关的呢?
如何判断搜索出的文档和查询语句的相关性呢?
这要回到我们第三个问题:如何对索引进行搜索?
搜索主要分为以下几步:
查询语句同我们普通的语言一样,也是有一定语法的。
不同的查询语句有不同的语法,如SQL语句就有一定的语法。
查询语句的语法根据全文检索系统的实现而不同。最基本的有比如:AND, OR, NOT等。
举个例子,用户输入语句:lucene AND learned NOT hadoop。
说明用户想找一个包含lucene和learned然而不包括hadoop的文档。
由于查询语句有语法,因而也要进行语法分析,语法分析及语言处理。
1. 词法分析主要用来识别单词和关键字。
如上述例子中,经过词法分析,得到单词有lucene,learned,hadoop, 关键字有AND, NOT。
如果在词法分析中发现不合法的关键字,则会出现错误。如lucene AMD learned,其中由于AND拼错,导致AMD作为一个普通的单词参与查询。
2. 语法分析主要是根据查询语句的语法规则来形成一棵语法树。
如果发现查询语句不满足语法规则,则会报错。如lucene NOT AND learned,则会出错。
如上述例子,lucene AND learned NOT hadoop形成的语法树如下:

3. 语言处理同索引过程中的语言处理几乎相同。
如learned变成learn等。
经过第二步,我们得到一棵经过语言处理的语法树。

此步骤有分几小步:
虽然在上一步,我们得到了想要的文档,然而对于查询结果应该按照与查询语句的相关性进行排序,越相关者越靠前。
如何计算文档和查询语句的相关性呢?
不如我们把查询语句看作一片短小的文档,对文档与文档之间的相关性(relevance)进行打分(scoring),分数高的相关性好,就应该排在前面。
那么又怎么对文档之间的关系进行打分呢?
这可不是一件容易的事情,首先我们看一看判断人之间的关系吧。
首先看一个人,往往有很多要素,如性格,信仰,爱好,衣着,高矮,胖瘦等等。
其次对于人与人之间的关系,不同的要素重要性不同,性格,信仰,爱好可能重要些,衣着,高矮,胖瘦可能就不那么重要了,所以具有相同或相似性格,信仰,爱好的人比较容易成为好的朋友,然而衣着,高矮,胖瘦不同的人,也可以成为好的朋友。
因而判断人与人之间的关系,首先要找出哪些要素对人与人之间的关系最重要,比如性格,信仰,爱好。其次要判断两个人的这些要素之间的关系,比如一个人性格开朗,另一个人性格外向,一个人信仰佛教,另一个信仰上帝,一个人爱好打篮球,另一个爱好踢足球。我们发现,两个人在性格方面都很积极,信仰方面都很善良,爱好方面都爱运动,因而两个人关系应该会很好。
我们再来看看公司之间的关系吧。
首先看一个公司,有很多人组成,如总经理,经理,首席技术官,普通员工,保安,门卫等。
其次对于公司与公司之间的关系,不同的人重要性不同,总经理,经理,首席技术官可能更重要一些,普通员工,保安,门卫可能较不重要一点。所以如果两个公司总经理,经理,首席技术官之间关系比较好,两个公司容易有比较好的关系。然而一位普通员工就算与另一家公司的一位普通员工有血海深仇,怕也难影响两个公司之间的关系。
因而判断公司与公司之间的关系,首先要找出哪些人对公司与公司之间的关系最重要,比如总经理,经理,首席技术官。其次要判断这些人之间的关系,不如两家公司的总经理曾经是同学,经理是老乡,首席技术官曾是创业伙伴。我们发现,两家公司无论总经理,经理,首席技术官,关系都很好,因而两家公司关系应该会很好。
分析了两种关系,下面看一下如何判断文档之间的关系了。
首先,一个文档有很多词(Term)组成,如search, lucene, full-text, this, a, what等。
其次对于文档之间的关系,不同的Term重要性不同,比如对于本篇文档,search, Lucene, full-text就相对重要一些,this, a , what可能相对不重要一些。所以如果两篇文档都包含search, Lucene,fulltext,这两篇文档的相关性好一些,然而就算一篇文档包含this, a, what,另一篇文档不包含this, a, what,也不能影响两篇文档的相关性。
因而判断文档之间的关系,首先找出哪些词(Term)对文档之间的关系最重要,如search, Lucene, fulltext。然后判断这些词(Term)之间的关系。
找出词(Term)对文档的重要性的过程称为计算词的权重(Term weight)的过程。
计算词的权重(term weight)有两个参数,第一个是词(Term),第二个是文档(Document)。
词的权重(Term weight)表示此词(Term)在此文档中的重要程度,越重要的词(Term)有越大的权重(Term weight),因而在计算文档之间的相关性中将发挥更大的作用。
判断词(Term)之间的关系从而得到文档相关性的过程应用一种叫做向量空间模型的算法(Vector Space Model)。
下面仔细分析一下这两个过程:
影响一个词(Term)在一篇文档中的重要性主要有两个因素:
容易理解吗?词(Term)在文档中出现的次数越多,说明此词(Term)对该文档越重要,如“搜索”这个词,在本文档中出现的次数很多,说明本文档主要就是讲这方面的事的。然而在一篇英语文档中,this出现的次数更多,就说明越重要吗?不是的,这是由第二个因素进行调整,第二个因素说明,有越多的文档包含此词(Term), 说明此词(Term)太普通,不足以区分这些文档,因而重要性越低。
这也如我们程序员所学的技术,对于程序员本身来说,这项技术掌握越深越好(掌握越深说明花时间看的越多,tf越大),找工作时越有竞争力。然而对于所有程序员来说,这项技术懂得的人越少越好(懂得的人少df小),找工作越有竞争力。人的价值在于不可替代性就是这个道理。
道理明白了,我们来看看公式:


这仅仅只term weight计算公式的简单典型实现。实现全文检索系统的人会有自己的实现,Lucene就与此稍有不同。
我们把文档看作一系列词(Term),每一个词(Term)都有一个权重(Term weight),不同的词(Term)根据自己在文档中的权重来影响文档相关性的打分计算。
于是我们把所有此文档中词(term)的权重(term weight) 看作一个向量。
Document = {term1, term2, …… ,term N}
Document Vector = {weight1, weight2, …… ,weight N}
同样我们把查询语句看作一个简单的文档,也用向量来表示。
Query = {term1, term 2, …… , term N}
Query Vector = {weight1, weight2, …… , weight N}
我们把所有搜索出的文档向量及查询向量放到一个N维空间中,每个词(term)是一维。
如图:

我们认为两个向量之间的夹角越小,相关性越大。
所以我们计算夹角的余弦值作为相关性的打分,夹角越小,余弦值越大,打分越高,相关性越大。
有人可能会问,查询语句一般是很短的,包含的词(Term)是很少的,因而查询向量的维数很小,而文档很长,包含词(Term)很多,文档向量维数很大。你的图中两者维数怎么都是N呢?
在这里,既然要放到相同的向量空间,自然维数是相同的,不同时,取二者的并集,如果不含某个词(Term)时,则权重(Term Weight)为0。
相关性打分公式如下:

举个例子,查询语句有11个Term,共有三篇文档搜索出来。其中各自的权重(Term weight),如下表格。
| t10 | t11 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| .477 | .477 | .176 | .176 | ||||||||
| .176 | .477 | .954 | .176 | ||||||||
| .176 | .176 | .176 | .176 | ||||||||
| .176 | .477 | .176 |
于是计算,三篇文档同查询语句的相关性打分分别为:


于是文档二相关性最高,先返回,其次是文档一,最后是文档三。
到此为止,我们可以找到我们最想要的文档了。
说了这么多,其实还没有进入到Lucene,而仅仅是信息检索技术(Information retrieval)中的基本理论,然而当我们看过Lucene后我们会发现,Lucene是对这种基本理论的一种基本的的实践。所以在以后分析Lucene的文章中,会常常看到以上理论在Lucene中的应用。
在进入Lucene之前,对上述索引创建和搜索过程所一个总结,如图:
此图参照www.lucene.com.cn/about.htm中文章《开放源代码的全文检索引擎Lucene》

1. 索引过程:
1) 有一系列被索引文件
2) 被索引文件经过语法分析和语言处理形成一系列词(Term)。
3) 经过索引创建形成词典和反向索引表。
4) 通过索引存储将索引写入硬盘。
2. 搜索过程:
a) 用户输入查询语句。
b) 对查询语句经过语法分析和语言分析得到一系列词(Term)。
c) 通过语法分析得到一个查询树。
d) 通过索引存储将索引读入到内存。
e) 利用查询树搜索索引,从而得到每个词(Term)的文档链表,对文档链表进行交,差,并得到结果文档。
f) 将搜索到的结果文档对查询的相关性进行排序。
g) 返回查询结果给用户。
下面我们可以进入Lucene的世界了。
CSDN中此文章链接为blog.csdn.net/forfuture19…
Javaeye中此文章链接为forfuture1978.javaeye.com/blog/546771
代码我已放到 Github ,导入spring-boot-lucene-demo 项目
github spring-boot-lucene-demo
1 | <!--对分词索引查询解析--><dependency> <groupId>org.apache.lucene</groupId> lucene-queryparser <version>7.1.0</version></dependency> <!--高亮 --><dependency> <groupId>org.apache.lucene</groupId> lucene-highlighter <version>7.1.0</version></dependency> <!--smartcn 中文分词器 SmartChineseAnalyzer smartcn分词器 需要lucene依赖 且和lucene版本同步--><dependency> <groupId>org.apache.lucene</groupId> lucene-analyzers-smartcn <version>7.1.0</version></dependency> <!--ik-analyzer 中文分词器--><dependency> <groupId>cn.bestwu</groupId> ik-analyzers <version>5.1.0</version></dependency> <!--MMSeg4j 分词器--><dependency> <groupId>com.chenlb.mmseg4j</groupId> mmseg4j-solr <version>2.4.0</version> <exclusions> <exclusion> <groupId>org.apache.solr</groupId> solr-core </exclusion> </exclusions></dependency> |
1 | private Directory directory; private IndexReader indexReader; private IndexSearcher indexSearcher; @Beforepublic void setUp() throws IOException { //索引存放的位置,设置在当前目录中 directory = FSDirectory.open(Paths.get("indexDir/")); //创建索引的读取器 indexReader = DirectoryReader.open(directory); //创建一个索引的查找器,来检索索引库 indexSearcher = new IndexSearcher(indexReader);} @Afterpublic void tearDown() throws Exception { indexReader.close();} ** * 执行查询,并打印查询到的记录数 * * @param query * @throws IOException */public void executeQuery(Query query) throws IOException { TopDocs topDocs = indexSearcher.search(query, 100); //打印查询到的记录数 System.out.println("总共查询到" + topDocs.totalHits + "个文档"); for (ScoreDoc scoreDoc : topDocs.scoreDocs) { //取得对应的文档对象 Document document = indexSearcher.doc(scoreDoc.doc); System.out.println("id:" + document.get("id")); System.out.println("title:" + document.get("title")); System.out.println("content:" + document.get("content")); }} /** * 分词打印 * * @param analyzer * @param text * @throws IOException */public void printAnalyzerDoc(Analyzer analyzer, String text) throws IOException { TokenStream tokenStream = analyzer.tokenStream("content", new StringReader(text)); CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class); try { tokenStream.reset(); while (tokenStream.incrementToken()) { System.out.println(charTermAttribute.toString()); } tokenStream.end(); } finally { tokenStream.close(); analyzer.close(); }} |
1 | @Testpublic void indexWriterTest() throws IOException { long start = System.currentTimeMillis(); //索引存放的位置,设置在当前目录中 Directory directory = FSDirectory.open(Paths.get("indexDir/")); //在 6.6 以上版本中 version 不再是必要的,并且,存在无参构造方法,可以直接使用默认的 StandardAnalyzer 分词器。 Version version = Version.LUCENE_7_1_0; //Analyzer analyzer = new StandardAnalyzer(); // 标准分词器,适用于英文 //Analyzer analyzer = new SmartChineseAnalyzer();//中文分词 //Analyzer analyzer = new ComplexAnalyzer();//中文分词 //Analyzer analyzer = new IKAnalyzer();//中文分词 Analyzer analyzer = new IKAnalyzer();//中文分词 //创建索引写入配置 IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer); //创建索引写入对象 IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig); //创建Document对象,存储索引 Document doc = new Document(); int id = 1; //将字段加入到doc中 doc.add(new IntPoint("id", id)); doc.add(new StringField("title", "Spark", Field.Store.YES)); doc.add(new TextField("content", "Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎", Field.Store.YES)); doc.add(new StoredField("id", id)); //将doc对象保存到索引库中 indexWriter.addDocument(doc); indexWriter.commit(); //关闭流 indexWriter.close(); long end = System.currentTimeMillis(); System.out.println("索引花费了" + (end - start) + " 毫秒");} |
响应
1 | 17:58:14.655 [main] DEBUG org.wltea.analyzer.dic.Dictionary - 加载扩展词典:ext.dic17:58:14.660 [main] DEBUG org.wltea.analyzer.dic.Dictionary - 加载扩展停止词典:stopword.dic索引花费了879 毫秒 |
1 | @Testpublic void deleteDocumentsTest() throws IOException { //Analyzer analyzer = new StandardAnalyzer(); // 标准分词器,适用于英文 //Analyzer analyzer = new SmartChineseAnalyzer();//中文分词 //Analyzer analyzer = new ComplexAnalyzer();//中文分词 //Analyzer analyzer = new IKAnalyzer();//中文分词 Analyzer analyzer = new IKAnalyzer();//中文分词 //创建索引写入配置 IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer); //创建索引写入对象 IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig); // 删除title中含有关键词“Spark”的文档 long count = indexWriter.deleteDocuments(new Term("title", "Spark")); // 除此之外IndexWriter还提供了以下方法: // DeleteDocuments(Query query):根据Query条件来删除单个或多个Document // DeleteDocuments(Query[] queries):根据Query条件来删除单个或多个Document // DeleteDocuments(Term term):根据Term来删除单个或多个Document // DeleteDocuments(Term[] terms):根据Term来删除单个或多个Document // DeleteAll():删除所有的Document //使用IndexWriter进行Document删除操作时,文档并不会立即被删除,而是把这个删除动作缓存起来,当IndexWriter.Commit()或IndexWriter.Close()时,删除操作才会被真正执行。 indexWriter.commit(); indexWriter.close(); System.out.println("删除完成:" + count);} |
响应
1 | 删除完成:1 |
1 | /** * 测试更新 * 实际上就是删除后新增一条 * * @throws IOException */@Testpublic void updateDocumentTest() throws IOException { //Analyzer analyzer = new StandardAnalyzer(); // 标准分词器,适用于英文 //Analyzer analyzer = new SmartChineseAnalyzer();//中文分词 //Analyzer analyzer = new ComplexAnalyzer();//中文分词 //Analyzer analyzer = new IKAnalyzer();//中文分词 Analyzer analyzer = new IKAnalyzer();//中文分词 //创建索引写入配置 IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer); //创建索引写入对象 IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig); Document doc = new Document(); int id = 1; doc.add(new IntPoint("id", id)); doc.add(new StringField("title", "Spark", Field.Store.YES)); doc.add(new TextField("content", "Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎", Field.Store.YES)); doc.add(new StoredField("id", id)); long count = indexWriter.updateDocument(new Term("id", "1"), doc); System.out.println("更新文档:" + count); indexWriter.close();} |
响应
1 | 更新文档:1 |
1 | /** * 按词条搜索 * <p> * TermQuery是最简单、也是最常用的Query。TermQuery可以理解成为“词条搜索”, * 在搜索引擎中最基本的搜索就是在索引中搜索某一词条,而TermQuery就是用来完成这项工作的。 * 在Lucene中词条是最基本的搜索单位,从本质上来讲一个词条其实就是一个名/值对。 * 只不过这个“名”是字段名,而“值”则表示字段中所包含的某个关键字。 * * @throws IOException */@Testpublic void termQueryTest() throws IOException { String searchField = "title"; //这是一个条件查询的api,用于添加条件 TermQuery query = new TermQuery(new Term(searchField, "Spark")); //执行查询,并打印查询到的记录数 executeQuery(query);} |
响应
1 | 总共查询到1个文档id:1title:Sparkcontent:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎! |
1 | /** * 多条件查询 * * BooleanQuery也是实际开发过程中经常使用的一种Query。 * 它其实是一个组合的Query,在使用时可以把各种Query对象添加进去并标明它们之间的逻辑关系。 * BooleanQuery本身来讲是一个布尔子句的容器,它提供了专门的API方法往其中添加子句, * 并标明它们之间的关系,以下代码为BooleanQuery提供的用于添加子句的API接口: * * @throws IOException */@Testpublic void BooleanQueryTest() throws IOException { String searchField1 = "title"; String searchField2 = "content"; Query query1 = new TermQuery(new Term(searchField1, "Spark")); Query query2 = new TermQuery(new Term(searchField2, "Apache")); BooleanQuery.Builder builder = new BooleanQuery.Builder(); // BooleanClause用于表示布尔查询子句关系的类, // 包 括: // BooleanClause.Occur.MUST, // BooleanClause.Occur.MUST_NOT, // BooleanClause.Occur.SHOULD。 // 必须包含,不能包含,可以包含三种.有以下6种组合: // // 1.MUST和MUST:取得连个查询子句的交集。 // 2.MUST和MUST_NOT:表示查询结果中不能包含MUST_NOT所对应得查询子句的检索结果。 // 3.SHOULD与MUST_NOT:连用时,功能同MUST和MUST_NOT。 // 4.SHOULD与MUST连用时,结果为MUST子句的检索结果,但是SHOULD可影响排序。 // 5.SHOULD与SHOULD:表示“或”关系,最终检索结果为所有检索子句的并集。 // 6.MUST_NOT和MUST_NOT:无意义,检索无结果。 builder.add(query1, BooleanClause.Occur.SHOULD); builder.add(query2, BooleanClause.Occur.SHOULD); BooleanQuery query = builder.build(); //执行查询,并打印查询到的记录数 executeQuery(query);} |
响应
1 | 总共查询到1个文档id:1title:Sparkcontent:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎! |
1 | /** * 匹配前缀 * <p> * PrefixQuery用于匹配其索引开始以指定的字符串的文档。就是文档中存在xxx% * <p> * * @throws IOException */@Testpublic void prefixQueryTest() throws IOException { String searchField = "title"; Term term = new Term(searchField, "Spar"); Query query = new PrefixQuery(term); //执行查询,并打印查询到的记录数 executeQuery(query);} |
响应
1 | 总共查询到1个文档id:1title:Sparkcontent:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎! |
1 | /** * 短语搜索 * <p> * 所谓PhraseQuery,就是通过短语来检索,比如我想查“big car”这个短语, * 那么如果待匹配的document的指定项里包含了"big car"这个短语, * 这个document就算匹配成功。可如果待匹配的句子里包含的是“big black car”, * 那么就无法匹配成功了,如果也想让这个匹配,就需要设定slop, * 先给出slop的概念:slop是指两个项的位置之间允许的最大间隔距离 * * @throws IOException */@Testpublic void phraseQueryTest() throws IOException { String searchField = "content"; String query1 = "apache"; String query2 = "spark"; PhraseQuery.Builder builder = new PhraseQuery.Builder(); builder.add(new Term(searchField, query1)); builder.add(new Term(searchField, query2)); builder.setSlop(0); PhraseQuery phraseQuery = builder.build(); //执行查询,并打印查询到的记录数 executeQuery(phraseQuery);} |
响应
1 | 总共查询到1个文档id:1title:Sparkcontent:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎! |
1 | /** * 相近词语搜索 * <p> * FuzzyQuery是一种模糊查询,它可以简单地识别两个相近的词语。 * * @throws IOException */@Testpublic void fuzzyQueryTest() throws IOException { String searchField = "content"; Term t = new Term(searchField, "大规模"); Query query = new FuzzyQuery(t); //执行查询,并打印查询到的记录数 executeQuery(query);} |
响应
1 | 总共查询到1个文档id:1title:Sparkcontent:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎! |
1 | /** * 通配符搜索 * <p> * Lucene也提供了通配符的查询,这就是WildcardQuery。 * 通配符“?”代表1个字符,而“*”则代表0至多个字符。 * * @throws IOException */@Testpublic void wildcardQueryTest() throws IOException { String searchField = "content"; Term term = new Term(searchField, "大*规模"); Query query = new WildcardQuery(term); //执行查询,并打印查询到的记录数 executeQuery(query);} |
响应
1 | 总共查询到1个文档id:1title:Sparkcontent:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎! |
1 | /** * 分词查询 * * @throws IOException * @throws ParseException */@Testpublic void queryParserTest() throws IOException, ParseException { //Analyzer analyzer = new StandardAnalyzer(); // 标准分词器,适用于英文 //Analyzer analyzer = new SmartChineseAnalyzer();//中文分词 //Analyzer analyzer = new ComplexAnalyzer();//中文分词 //Analyzer analyzer = new IKAnalyzer();//中文分词 Analyzer analyzer = new IKAnalyzer();//中文分词 String searchField = "content"; //指定搜索字段和分析器 QueryParser parser = new QueryParser(searchField, analyzer); //用户输入内容 Query query = parser.parse("计算引擎"); //执行查询,并打印查询到的记录数 executeQuery(query);} |
响应
1 | 总共查询到1个文档id:1title:Sparkcontent:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎! |
1 | /** * 多个 Field 分词查询 * * @throws IOException * @throws ParseException */@Testpublic void multiFieldQueryParserTest() throws IOException, ParseException { //Analyzer analyzer = new StandardAnalyzer(); // 标准分词器,适用于英文 //Analyzer analyzer = new SmartChineseAnalyzer();//中文分词 //Analyzer analyzer = new ComplexAnalyzer();//中文分词 //Analyzer analyzer = new IKAnalyzer();//中文分词 Analyzer analyzer = new IKAnalyzer();//中文分词 String[] filedStr = new String[]{"title", "content"}; //指定搜索字段和分析器 QueryParser queryParser = new MultiFieldQueryParser(filedStr, analyzer); //用户输入内容 Query query = queryParser.parse("Spark"); //执行查询,并打印查询到的记录数 executeQuery(query);} |
响应
1 | 总共查询到1个文档id:1title:Sparkcontent:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎! |
1 | /** * IKAnalyzer 中文分词器 * SmartChineseAnalyzer smartcn分词器 需要lucene依赖 且和lucene版本同步 * * @throws IOException */@Testpublic void AnalyzerTest() throws IOException { //Analyzer analyzer = new StandardAnalyzer(); // 标准分词器,适用于英文 //Analyzer analyzer = new SmartChineseAnalyzer();//中文分词 //Analyzer analyzer = new ComplexAnalyzer();//中文分词 //Analyzer analyzer = new IKAnalyzer();//中文分词 Analyzer analyzer = null; String text = "Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎"; analyzer = new IKAnalyzer();//IKAnalyzer 中文分词 printAnalyzerDoc(analyzer, text); System.out.println(); analyzer = new ComplexAnalyzer();//MMSeg4j 中文分词 printAnalyzerDoc(analyzer, text); System.out.println(); analyzer = new SmartChineseAnalyzer();//Lucene 中文分词器 printAnalyzerDoc(analyzer, text);} |
三种分词响应
1 | apachespark专为大规模规模模数数据处理数据处理而设设计快速通用计算引擎 |
1 | apachespark是专为大规模数据处理而设计的快速通用的计算引擎 |
1 | apachspark是专为大规模数据处理而设计的快速通用的计算引擎 |
1 | /** * 高亮处理 * * @throws IOException */@Testpublic void HighlighterTest() throws IOException, ParseException, InvalidTokenOffsetsException { //Analyzer analyzer = new StandardAnalyzer(); // 标准分词器,适用于英文 //Analyzer analyzer = new SmartChineseAnalyzer();//中文分词 //Analyzer analyzer = new ComplexAnalyzer();//中文分词 //Analyzer analyzer = new IKAnalyzer();//中文分词 Analyzer analyzer = new IKAnalyzer();//中文分词 String searchField = "content"; String text = "Apache Spark 大规模数据处理"; //指定搜索字段和分析器 QueryParser parser = new QueryParser(searchField, analyzer); //用户输入内容 Query query = parser.parse(text); TopDocs topDocs = indexSearcher.search(query, 100); // 关键字高亮显示的html标签,需要导入lucene-highlighter-xxx.jar SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("", ""); Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new QueryScorer(query)); for (ScoreDoc scoreDoc : topDocs.scoreDocs) { //取得对应的文档对象 Document document = indexSearcher.doc(scoreDoc.doc); // 内容增加高亮显示 TokenStream tokenStream = analyzer.tokenStream("content", new StringReader(document.get("content"))); String content = highlighter.getBestFragment(tokenStream, document.get("content")); System.out.println(content); } } |
响应
1 | Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎! |
代码我已放到 Github ,导入spring-boot-lucene-demo 项目
github spring-boot-lucene-demo
微信公众号【程序员黄小斜】新生代青年聚集地,程序员成长充电站。作者黄小斜,职业是阿里程序员,身份是斜杠青年,希望和更多的程序员交朋友,一起进步和成长!这一次,我们一起出发。
关注公众号后回复“2019”领取我这两年整理的学习资料,涵盖自学编程、求职面试、算法刷题、Java技术、计算机基础和考研等8000G资料合集。
微信公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,专注于 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
关注公众号后回复“PDF”即可领取200+页的《Java工程师面试指南》强烈推荐,几乎涵盖所有Java工程师必知必会的知识点。